- Published on
LLM 文本生成解码策略指南(一)
- Authors

- Name
- Jason Huang
- @zesenhhh
本文将深入探讨几种常见的解码方式,例如贪婪搜索、Beam Search 以及 top-k、top-p 采样等,并分析它们各自的优缺点、适用场景以及如何在 HuggingFace 的 transformer 库中使用。
在自然语言处理领域,解码策略是连接模型与文本生成的关键桥梁。它决定了模型如何将内部的概率分布转化为最终呈现的文字序列。本文正是探讨这一核心机制的切入点。
对于一个预训练好的语言模型如 GPT,其强大的生成能力并非仅仅来自于庞大的参数量和精妙的网络结构,解码方式的选择同样至关重要。解码策略如同模型的“翻译官”,将模型内部抽象的 token 概率分布转化为我们理解的自然语言。不同的解码方法,如同不同的翻译风格,深刻影响着生成文本的质量、多样性和可控性。
因此,理解并选择合适的解码策略对于充分发挥预训练语言模型的潜力至关重要,它直接决定了模型最终输出的文本是否能够满足我们的需求。
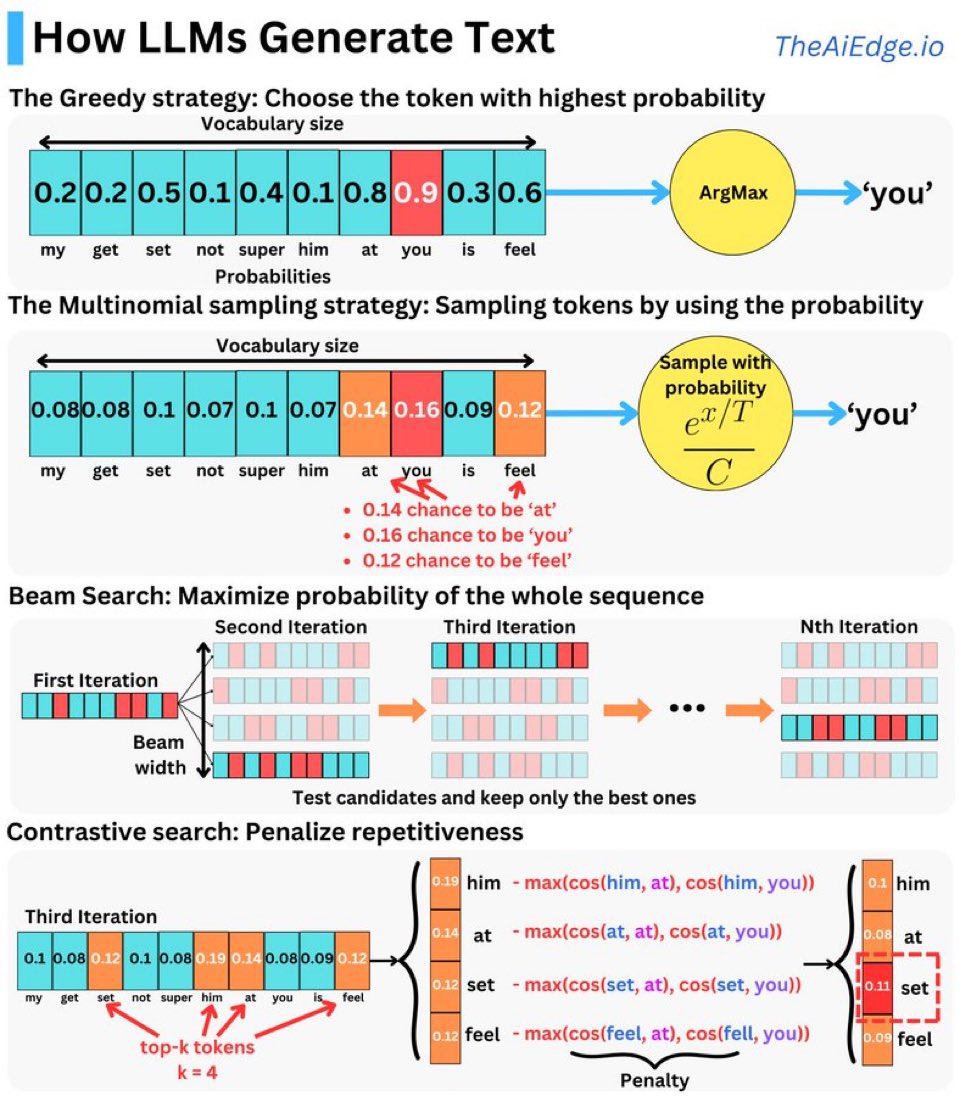 图 1
图 1
贪婪搜索
贪婪搜索(Greedy Search)选择具有最高概率的标记。
在这种策略下,模型从给定的词汇表中选择概率最高的单词。例如,在上图中,you 具有 0.9 的最高概率,因此模型直接选择它作为下一个生成的单词。
这种策略简单直接,但可能会错过更好的整体序列,因为它只关注单个标记的最高概率。
举个例子: 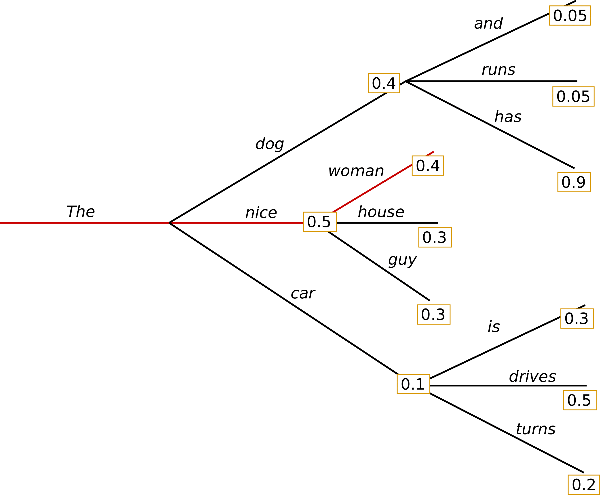 图 2
图 2
假设上图为某一模型生成过程中的概率分布,单词 has 具有高条件概率 0.9,隐藏在单词 dog 之后,而 dog 只有第二高的条件概率,因此贪婪搜索错过了单词序列 the, dog ,has(0.4* 0.9),而选择了 the,nice,woman(0.5 * 0.4)。
在 transformer 这个库中,模型的 generate 生成文本的方法默认使用贪婪搜索解码,因此无需传递任何参数即可启用。这意味着参数 num_beams 默认设置为 1, do_sample 默认设置为 False (num_beams 与 do_sample 这两个参数可用于其他解码策略,下文会讲到)。
from transformers import AutoModelForCausalLM, AutoTokenizer
prompt = "I look forward to"
checkpoint = "distilbert/distilgpt2"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(checkpoint)
outputs = model.generate(**inputs)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
束搜索
束搜索(Beam Search) 最大化整个序列的概率。
Beam Search 通过保持多个候选序列(“beam”)并在每次迭代中选择最有可能的序列来最大化整个句子的概率。每次迭代,都会测试多个候选项,并保留最优的。
它是一种权衡速度和质量的方法,通过扩大 beam width,可以考虑更多的可能性,但计算复杂度也会增加。
在上个例子中,Beam Search 就可以找到联合概率最大的 the, dog ,has(0.4* 0.9)。
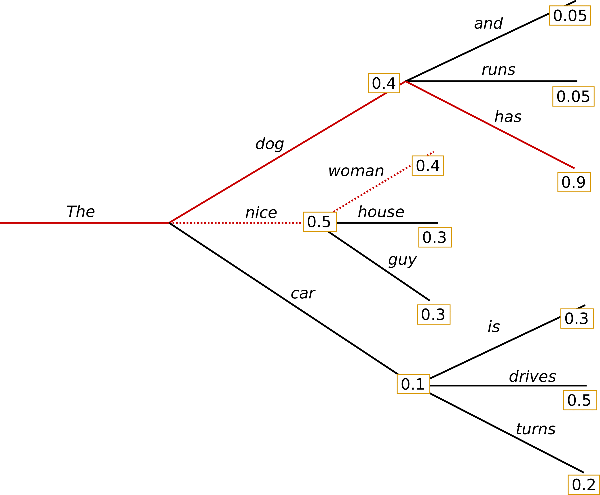 图 3
图 3
IMPORTANT
Beam Search 总是能找到一个比贪婪搜索概率更高的输出序列,但并不保证找到最可能的输出。
在机器翻译或摘要等任务中,所需的生成长度或多或少是可以预测的,在这种情况下,Beam Search 可以很好地发挥作用(参考 Murray et al. (2018) 和 Yang et al. (2018)),但对于开放式生成来说,情况并非如此。
正如 Ari Holtzman et al. (2019) 中所论证的,高质量的人类语言并不遵循高概率下一个词的分布。换句话说,作为人类,我们希望生成的文本能给我们带来惊喜,而不是枯燥乏味/不可预测的。
要启用这种 Beam Search 解码策略,需要在指定 num_beams (也就是要跟踪的不同选择的序列长度)大于 1。
from transformers import AutoModelForCausalLM, AutoTokenizer
prompt = "It is astonishing how one can"
checkpoint = "openai-community/gpt2-medium"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(checkpoint)
outputs = model.generate(**inputs, num_beams=5, max_new_tokens=50)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
多项式采样
多项式采样(Multinomial sampling)按概率采样标记。
该策略不总是选择概率最高的标记,而是基于概率分布进行随机采样。例如 图 1 中第二行,you 的概率为 0.16,at 为 0.14,而 feel 为 0.12。在这种情况下,模型有更大的概率选择 you,但 at 和 feel 也有一定的选择可能性。
这种策略引入了随机性,增加了生成文本的多样性。
do_sample 设置为 True 即可开始在候选词汇中进行随机采样。
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
set_seed(0) # For reproducibility
checkpoint = "openai-community/gpt2-large"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
prompt = "Today was an amazing day because"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, do_sample=True, num_beams=1, max_new_tokens=100)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
Top-K 采样
Top-K 采样是一种改进的多项式采样方法。它只考虑概率最高的 k 个标记,然后从中进行随机采样。这有效地减少了低概率标记的干扰,并提高了生成文本的质量和连贯性。
在 Top-K 抽样中,K 个最有可能的下一个词被筛选出来,概率质量只在这些 K 个下一个词中重新分配。GPT2 采用了这种抽样方案,这也是它在故事生成方面取得成功的原因之一。
例如,如果 k=3,模型只会在概率最高的三个 token 中进行采样,忽略其余的标记。这避免了模型选择一些概率极低的、毫无意义的单词,从而提高了生成文本的质量。 k 值的选择是一个超参数,需要根据具体任务进行调整。较小的 k 值会产生更连贯但可能较少多样性的文本,而较大的 k 值则会增加多样性但可能降低连贯性。
保持 do_sample 为 True 的同时,设置 top_k 大于 1 激活 Top-K 采样:
sample_output = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_k=50
)
Top-p 采样
Top-p 采样,也称为 Nucleus 采样,是一种更灵活的采样方法。它选择概率累加超过 p 的所有标记,然后从中进行随机采样,而不限制固定的数量。p 值表示累积概率的阈值。与 Top-k 采样相比,Top-p 采样动态地选择要考虑的标记数量,使其更适应不同的概率分布。如果概率分布非常集中,Top-p 采样可能会选择较少的标记;如果概率分布比较分散,则可能会选择较多的标记。这使得 Top-p 采样在处理不同类型的文本时更具鲁棒性。
虽然从理论上讲,Top-p 似乎比 Top-K 更优雅,但这两种方法在实践中都很有效。Top-p 还可以与Top-K 结合使用,这样既可以避免排名很靠后的词,又可以进行一些动态选择。
设置 0 < top_p < 1 激活 Top-p 采样:
sample_output = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_p=0.92,
top_k=0
)
对比搜索
传统的解码策略,如上述的贪心解码、束搜索与采样解码都有各自的局限。
对比搜索(Contrastive Search)通过对生成文本中重复出现的标记进行惩罚,从而避免生成相似或重复的句子,这里简单提及一下,更详细的学习记录与解读将在下一篇中介绍。
在图 1 中最后一行,通过惩罚后,词 set 和 feel 的概率相对较小,因为它们与上下文(at 和 you)的相似性较高,导致被惩罚较多,而 at 自身概率则是最小的,避免重复生成。调整后的概率分布更新后,最终选取惩罚后得分最高的词作为下一个生成的 token。
这种策略有效地减少了文本生成中的重复性,提高了输出的多样性和质量。
除了本文提到的几种生成文本的解码策略,近年来还涌现出许多改进方法,在文本生成的多样性、流畅性、生成速度以及事实性等方面取得了显著进展。相关策略将在下一篇文章中详细介绍。
参考
- How to generate text: using different decoding methods for language generation with Transformers
- Text generation strategies

