- Published on
RAG 检索策略:BM25、Embedding 和 Reranker 万字深度解析
- Authors

- Name
- Jason Huang
- @zesenhhh
Table of Contents
检索增强生成(Retrieval Augmented Generation, RAG)已成为提升大型语言模型(LLM)回答准确性、时效性并减少幻觉的关键技术;RAG 最早由 Patrick Lewis 及其团队(Facebook AI Research)于 2020 年提出,首次系统阐述了结合检索器与生成模型的端到端训练框架。
RAG 的核心在于其“检索”模块的效率和准确性,检索模块的性能直接影响整体系统表现;本文将深入探讨主流的检索策略中经典的基于关键词的 BM25 算法和现代的基于语义的多种向量 Embedding 和 Reranker 机制。
IMPORTANT
传统的 BM25 算法检索能精准匹配关键词但忽略了语义信息,现代的向量 Embedding 检索能基于语义信息匹配但是不够精准;
没有哪一种检索策略是最好的,但是混合多种检索策略的效果优于单独的任何一种方法。
BM25
BM25(Best Matching 25)是一种经典的基于词袋模型的排序算法,广泛应用于搜索引擎和信息检索系统中,通过计算查询词项与文档中词项的匹配程度来对文档进行排序。
原理
BM25 的核心思想是综合考量以下几个因素:
- 词频(Term Frequency, TF): 一个词在文档中出现的频率。BM25 使用一种饱和的 函数,意味着词频的增加对得分的贡献会逐渐减小,避免高频词过度主导;
- 逆文档频率(Inverse Document Frequency, IDF): 一个词在整个文档集合中出现的普遍程度。越稀有的词, 值越高,说明其区分度越大。BM25 对 的计算进行了平滑处理,避免了未在任何文档中出现的词导致 为零或负数的情况;
- 文档长度归一化(Normalization): 较长的文档天然可能包含更多查询词,BM25 通过引入文档长度与平均文档长度的比较,对得分进行调整,以减少对长文档的偏袒。
BM25 的得分函数如下:
其中:
- :文档 对于查询 的 BM25 得分;
- :用户的查询,包含 个关键词;
- :关键词 在文档 中出现的频率(term frequency);
- :关键词 的逆文档频率(inverse document frequency);
- :文档 的长度(例如,包含的单词数);
- :所有文档的平均长度;
- :一个调节词频饱和度的参数,通常取值在 1.2 到 2.0 之间;
- :一个调节文档长度对得分影响的参数,通常取值为 0.75;
的计算公式通常为:
其中:
- :文档集合中的文档总数;
- :包含关键词 的文档数量;
整个公式背后的思想是:
- 对于查询中的每个词,计算其 值, 值越高,说明该词越重要;
- 计算每个词在文档中的词频 ,并使用 来调节词频饱和度;
- 使用文档长度 和平均文档长度 来对文档长度进行归一化,参数 控制归一化的程度;
- 将所有词的得分加起来,得到文档 对于查询 的最终得分,该得分越高表明文档 对于查询 越相关;
示例代码如下,这个例子主要考虑以英文为主,因为英文简单以空格分割就好了,但如果是中文的话,需要考虑用 jieba 分词,分词的影响还是比较大的。
import math
from collections import Counter, defaultdict
class BM25:
def __init__(self, documents, k1=1.5, b=0.75):
"""
BM25 算法实现
k1: 控制词频饱和度的参数 (通常 1.2-2.0)
b: 控制文档长度归一化的参数 (通常 0.75)
"""
self.k1 = k1
self.b = b
self.documents = documents
self.doc_count = len(documents)
self.doc_lengths = [len(doc.split()) for doc in documents]
self.avg_doc_length = sum(self.doc_lengths) / len(self.doc_lengths)
# 计算 IDF 和词频
self.word_doc_freq = defaultdict(int) # 每个词出现在多少个文档中
self.doc_word_freq = [] # 每个文档的词频统计
for doc in documents:
words = doc.lower().split()
word_freq = Counter(words)
self.doc_word_freq.append(word_freq)
# 统计词在多少个文档中出现
for word in set(words):
self.word_doc_freq[word] += 1
def get_idf(self, word):
"""计算词的 IDF 值"""
df = self.word_doc_freq.get(word, 0)
if df == 0:
return 0
return math.log((self.doc_count - df + 0.5) / (df + 0.5) + 1)
def get_score(self, query, doc_index):
"""计算查询和文档的 BM25 分数"""
query_words = query.lower().split()
doc_word_freq = self.doc_word_freq[doc_index]
doc_length = self.doc_lengths[doc_index]
score = 0
for word in query_words:
if word in doc_word_freq:
tf = doc_word_freq[word] # 词频
idf = self.get_idf(word) # 逆文档频率
# BM25 公式
numerator = tf * (self.k1 + 1)
denominator = tf + self.k1 * (1 - self.b + self.b * doc_length / self.avg_doc_length)
score += idf * (numerator / denominator)
return score
def search(self, query, top_k=None):
"""搜索并返回排序后的结果"""
scores = []
for i, doc in enumerate(self.documents):
score = self.get_score(query, i)
scores.append((score, i, doc))
# 按分数降序排列
scores.sort(key=lambda x: x[0], reverse=True)
if top_k:
scores = scores[:top_k]
return scores
如果查询中包含多个关键词,比如"微信公众号爆文"这个查询,我们假设分词成"微信"、"公众号"和"爆文",那该查询最终的 BM25 得分是"微信"、"公众号"和"爆文"这 3 个查询 Q 的 BM25 得分的综合结果。在 BM25 算法中,每个查询词(term)对文档的得分贡献是独立计算的,最终每个候选文档的得分通常是对所有查询词得分的累加:
score(D, Q) = score(D, 微信) + score(D, 公众号) + score(D, 爆文)
然后返回 topk 高分的候选文档作为搜索结果就好了。
BM25 算法的优势在于其简单高效,算法相对简单,计算速度快,易于实现和部署。对于关键词匹配明确的查询,BM25 通常能提供非常好的结果。此外,BM25 是基于统计的,不需要大规模的标注数据进行模型训练(特指其核心算法,而非参数调优),并且其得分基于明确的词频和文档频率统计,因此可解释性强,易于理解为何某个文档被认为是相关的。
然而,BM25 也存在一些劣势。它严重依赖分词和词汇的精确匹配,无法理解同义词、近义词或概念相关的查询,这导致了语义鸿沟问题。同时,作为一种词袋模型,BM25 忽略了词语的顺序和句子结构,这在处理需要考虑语序的复杂查询时可能会影响其效果。
全文搜索(Full text Search)、倒排索引(Inverted Index)与 BM25
搜索领域 BM25 经常与全文搜索(Full text Search)、倒排索引(Inverted Index)一起被提及,这是构建现代搜索系统的三个关键概念。
全文搜索、倒排索引和 BM25 三者之间有明确的层次和功能关系:全文搜索(Full Text Search)是整体功能,而倒排索引和BM25是实现这个功能的两个关键组件。
倒排索引(Inverted Index)是全文搜索的数据结构基础,它解决了"如何高效找到包含特定词的文档"的问题,本质上是一个映射表:词项→[文档ID列表];
BM25 是全文搜索的排序算法,它解决了"如何排列找到的文档"的问题,用于计算每个文档与查询的相关性分数。
在实际的搜索过程中:
- 用户输入查询词
- 系统通过倒排索引快速定位包含这些词的所有文档
- 使用BM25算法为每个文档计算相关性分数
- 按分数从高到低排序后返回结果
Embedding
在信息检索领域,BM25 虽然高效,但在理解文本的深层语义方面存在局限性。为了克服这一挑战,基于 Embedding(嵌入)的检索策略应运而生。至于什么是 Embedding,可以参考我的其他博客文章:机器学习中的向量化是什么?。
与依赖词频和逆文档频率的传统方法不同,Embedding 检索通过计算查询向量与文档向量之间的相似度(如余弦相似度、点积等)来进行相关性排序。这使得检索系统能够超越字面匹配,捕捉到词语、短语乃至整个文档的语义内涵,从而实现更智能、更精准的信息召回。
根据向量表示的特性,Embedding 检索策略主要可以分为 Sparse Embedding、Dense Embedding 以及 Multi-vector Embeddings。

上图中是几种不同类型的 embeddings 的区别:
- 稀疏嵌入:稀疏向量包含很多零值,通常是高维的。这类嵌入是由像 BM25 和 SPLADE 这样的算法生成的,常用于基于关键字的搜索。
- 密集嵌入:密集向量主要包含非零值,通常由机器学习模型生成。这类向量能够捕捉文本的语义含义,用于语义搜索。
- 量化嵌入:量化嵌入是压缩的密集向量,使用更低精度的数据类型(例如,将 float32 量化为 int8)。它可以减少内存使用,并加快搜索速度,同时保持大部分语义信息。
- 二进制嵌入:这是一种极端量化,向量中的每个分量都被简化为二进制值(0 或 1),显著减少了内存使用。
- 可变维度嵌入:这类嵌入支持灵活的向量长度(例如 Matryoshka embeddings),可以根据不同任务或限制进行调整,同时保留语义含义。
- 多向量嵌入:使用多个向量而不是一个聚合向量来表示信息(例如,逐 token 方式的嵌入,如 ColBERT),允许对复杂文本进行更详细的表示。
其中 3、4 和 5 可以算是 Dense Embedding 的不同版本。这些嵌入方法的核心区别在于它们在内存使用、精度、搜索效率以及信息表达的丰富性上各有侧重,适用于不同的应用场景。
Spare Embedding
Spare Embedding 的主要优点在于能够精确地匹配查询中的关键词,并且具有很强的可解释性,因为向量中的非零元素直接对应于文档中的重要词语。此外,由于向量的稀疏性,它们通常在存储和计算上更高效。
Spare Embedding 有两种生成的方式:BM25(TF-IDF) 和 SPLADE(SParse Lexical AnD Expansion model),本节将重点介绍 SPLADE 稀疏向量。
在 Embedding 的语境中,BM25 的方法指的是用其核心原理 TF-IDF 计算的数值作为 Embedding 来表示文档,相关性的分数则是通过计算两两 Embedding 之间的余弦相似度或者点积得出。
那怎么用 Embedding 表示文档?
首先,统计所有文档中出现过的词,构造一个词汇表(Vocabulary),这个词汇表是所有可能出现在向量中的维度。
对于每个文档,进行分词后(拉丁语系根据空格分词,中文可以用 jieba 进行分词),创建一个向量,向量的每个维度对应词汇表中的一个词。如果文档中包含该词,则该维度上的值为该词在文档中的权重,这个权重最简单的可以是用 1 表示有这个词,也可以用词频表示该词出现的次数,也可以用 TF-IDF 值表示这个词的“重要性”,如果文档中不包含该词,则该维度上的值为 0。
类似地,对于每个查询,创建一个向量,该向量构造与文档向量的构造一样。
最后,计算查询向量与所有文档向量之间的余弦相似度就可以得到相关性的分数,对该分数进行归一化之后,分数越大表示越相关。
举个例子: 假设词汇表为:["微信", "公众号", "爆文", "文章", "阅读"]
文档 D1: "微信公众号文章" -> 向量:[1, 1, 0, 1, 0] 查询 Q1: "公众号爆文" -> 向量:[0, 1, 1, 0, 0]
这里的 1 和 0 仅仅是示例,实际应用中会是 TF-IDF 相关的值。
SPLADE 原理
Spare Embedding 通常基于词袋模型,即这类向量的维度由词汇表的大小决定,每一维用一个数值表示对应词语在文本中的权重。SPLADE 也是建立在类似的基础之上,但有所不同的是,**SPLADE 利用 Transformer 为文档和查询的词分配权重,不仅能够表示文档中实际出现的词,还能够为与文本内容相关但未在文档中直接出现的词分配相应权重,从而实现语义拓展的效果。
SPLADE 采用基于 BERT 模型计算词权重并生成最终的稀疏向量,也就是说 SPLADE 在使用中是一个特别训练过的 BERT 模型,同时使用了 BERT 的 WordPiece 词汇表,词汇表大小 。
一个查询或文档作为输入时,经过 WordPiece 分词后,得到 token 序列 。这些 token 通过 BERT 模型编码,生成对应的上下文表示 ,其中 是第 个 token 在 BERT 嵌入,即 BERT 最后一层的输出, 对应为 768 维度的初始的 embedding(bert-base 为 768,bert-large 为 1024),其编码了 token 及其前后 token 的语义关系。
下方的公式描述了如何计算 token 对词汇表中每个词 的权重 :
- 第 个 token 的 BERT 嵌入(上下文表示)用 表示;
- 是一个线性层,它带有 GELU 激活函数和 LayerNorm,用于转换 ;
- 词汇表中第 个词的 BERT 输入嵌入用 表示,这是 BERT 预训练时使用的嵌入;
- 是词汇表中第 个词的偏置项(token-level bias),用于调整权重;
- 表示第 个 token 对词汇表中第 个词的“重要性”或“相关性”,维度与词汇表的大小一致(30522),表示 token 对所有词的打分。
这一步将 token 的上下文表示 映射到词汇表空间,通过与词汇表嵌入 的点积计算相似性,得到权重 ,其值可正可负,表示 token 和词 的关联程度(负值后续会被 ReLU 处理为 0)。因此,输入的查询或文档中的每个 token 都会得到一个长度为 的稀疏向量 ,表示它对词汇表中所有词的“重要性”或“相关性”。
然后通过以下方式将所有 token 的权重向量 聚合得到词汇表中每个词 的最终权重 :
- 表示 token 对词 的权重,如果输入的文本分词后有 5 个 token,那么就会有 5 个 进行聚合;
- ReLU 表示将 的负值置为 0,确保权重非负(稀疏性);
- 表示对输入序列中所有 token 的权重进行求和,聚合每个 token 对词 的贡献;
- 表示词汇表中第 个词的最终权重,反映了整个文档对词 的累计相关性。
最终的 表示词汇表中第 个词对输入序列的整体重要性,支持语义扩展(即使词 未出现在输入中,也可能有非零权重),文档是通过聚合得到的词汇表中每个词的权重 来表示的(类似 TF-IDF 的词袋模型表示),这就是我们最终想得到的 Spare Embedding。
举个例子,假设文档是"the cat sleeps",有 3 个 token,词汇表包含 [the, cat, sleeps, dog, run]:
对于 ,假设 对于"cat"本身很高,经过公式计算, 会是一个较大的正值。
对于 ,如果模型认为"cat"和"dog"语义相关, 可能小但为正, 也可能是非 0。
对于 ,如果与文档无关,,则 。
最终文档表示可能是:,其中 是相关词的贡献。
如何训练 SPLADE
SPLADE 的训练目标通常是联合优化检索性能和稀疏性。
为了让模型学会区分相关文档和无关文档,SPLADE 采用对比学习或排序损失函数。常用的损失函数为 noteNCE Loss(对比损失)。
IMPORTANT
对比学习是一种机器学习方法,对于 Embedding 模型有重要意义,其通过学习区分相似和不相似的数据点来训练模型,核心是学习一个表示空间(embedding),使相似样本距离较近,不相似样本距离较远。其目标是学习有结构的嵌入空间,保留语义相似性,去除无关扰动。
对比学习不是学习标签,而是学习相似性结构,是一种自监督的表征学习方法。其重要性在于能够学习有意义的表示,适用于缺乏标签的数据,提高下游任务性能,并解决模型坍塌问题。
InfoNCE 是一种广泛使用的对比学习损失,鼓励相关文档的得分高于无关文档:
其中:
- :查询(query)的稀疏表示。
- :与查询相关的正样本文档(relevant document)。
- :与查询无关的负样本文档(irrelevant document)。
- :负样本集合。
- :查询和文档稀疏向量的点积得分。
InfoNCE 通过最大化正样本的得分并最小化负样本的得分,优化模型的检索能力。
为了生成稀疏的向量表示,SPLADE 引入正则化项,限制稀疏向量中非零维度的数量。常用的正则化损失是 FLOPS 正则化,其目标是最小化计算点积时的浮点运算量(FLOPS)。
传统的 正则化虽然能促进稀疏,但并不能保证检索索引中各个倒排列表的权重分布均衡,而均衡分布对快速检索至关重要。“FLOPS” 本义是每秒浮点运算次数(Floating Point Operations per Second),在这里借用来衡量计算某个文档得分所需的浮点运算量,也就是影响检索延迟的关键因素。
先计算在一个小批量(batch)中,词表中第 个词的平均权重:
其中 是批量大小, 表示文档 在第 个维度(词)上的权重。
FLOPS 正则化的损失:
这里对平均权重 做平方,能够更加严厉地惩罚那些在所有文档中平均权重较高的词(即那些出现频率高、主导索引结构的常见词),从而推动整个词表权重分布更加均衡。
最终的联合损失函数的公式:
- 表示排名损失,比如 InfoNCE;
- 是查询的正则化损失, 是文档的正则化损失;
- 和 是查询和文档的正则化权重。通过分别设置这些权重,模型可以对查询和文档的稀疏性施加不同的压力。
通过这种训练方式,SPLADE 能够在保持稀疏性的同时,学习到语义丰富的表示,适用于高效的信息检索任务。
Dense Embedding
Dense Embedding,即密集嵌入,是将文本映射到一个相对低维(通常几百到几千维)且稠密的向量空间。与稀疏嵌入不同,Dense Embedding 中的每一个维度都具有非零值,并且这些维度通常不直接对应到特定的词汇,而是共同编码了文本的整体语义信息。
Dense Embedding 能够捕捉文本的语义相似性,即使查询和文档使用了不同的词语,只要它们在含义上相近,Embedding 仍然可以将它们识别出来。
Dense Embedding 的原理是使用神经网络模型,如 Word2Vec、GloVe 和 Transformer 架构的模型(例如 Sentence-BERT 和 BGE)等,来学习文本的连续向量表示。这些模型通过训练学习了大量的文本数据,将每个文本 token 映射到一个低维的实数向量,向量中的每个维度都编码了文本的某些语义特征。
不同的 Dense Embedding 模型在捕捉语义信息和上下文方面各有侧重。Word2Vec 和 GloVe 是较早的模型,它们通过分析词语在语料库中的共现模式来学习词向量,但它们生成的 Embedding 通常是静态且上下文无关的。
Word2Vec 在 NLP 的历史中意义重大,不过此类模型在本文不过多阐述,具体可以参考我的另一篇文章:从Word2Vec到Item2Vec,万物皆可嵌入(附Pytorch代码) ,该节将重点介绍在 RAG 中常用的 Dense Embedding 模型,这类模型能够生成上下文相关的词 Embedding,即同一个词在不同的语境下会有不同的向量表示,这使得它们在理解复杂的语义关系方面更加强大。
Sentence-BERT
BERT 本身的设计并不是为了直接生成句子的固定向量,而 Sentence-BERT 是一种专门为获取句子级语义表示而设计的模型。它是对原始 BERT 的改进版本,使其能高效地产生句子的向量表示,以便进行句子相似度计算、语义检索、聚类等任务。
在原始 BERT 模型中,[CLS] token 的嵌入(通常是输出矩阵的第一行)常被用作句子的整体表示,特别是在分类任务中。但在 Sentence-BERT 中,作者选择通过池化操作(例如均值池化或最大池化)来从所有 token 的嵌入中生成句子嵌入,而不是直接使用 [CLS] token 的嵌入。这是 Sentence-BERT 的一个关键改进,因为研究表明池化操作生成的句子嵌入在语义相似性任务中表现更好。
Sentence-BERT 的架构和训练流程图如下:
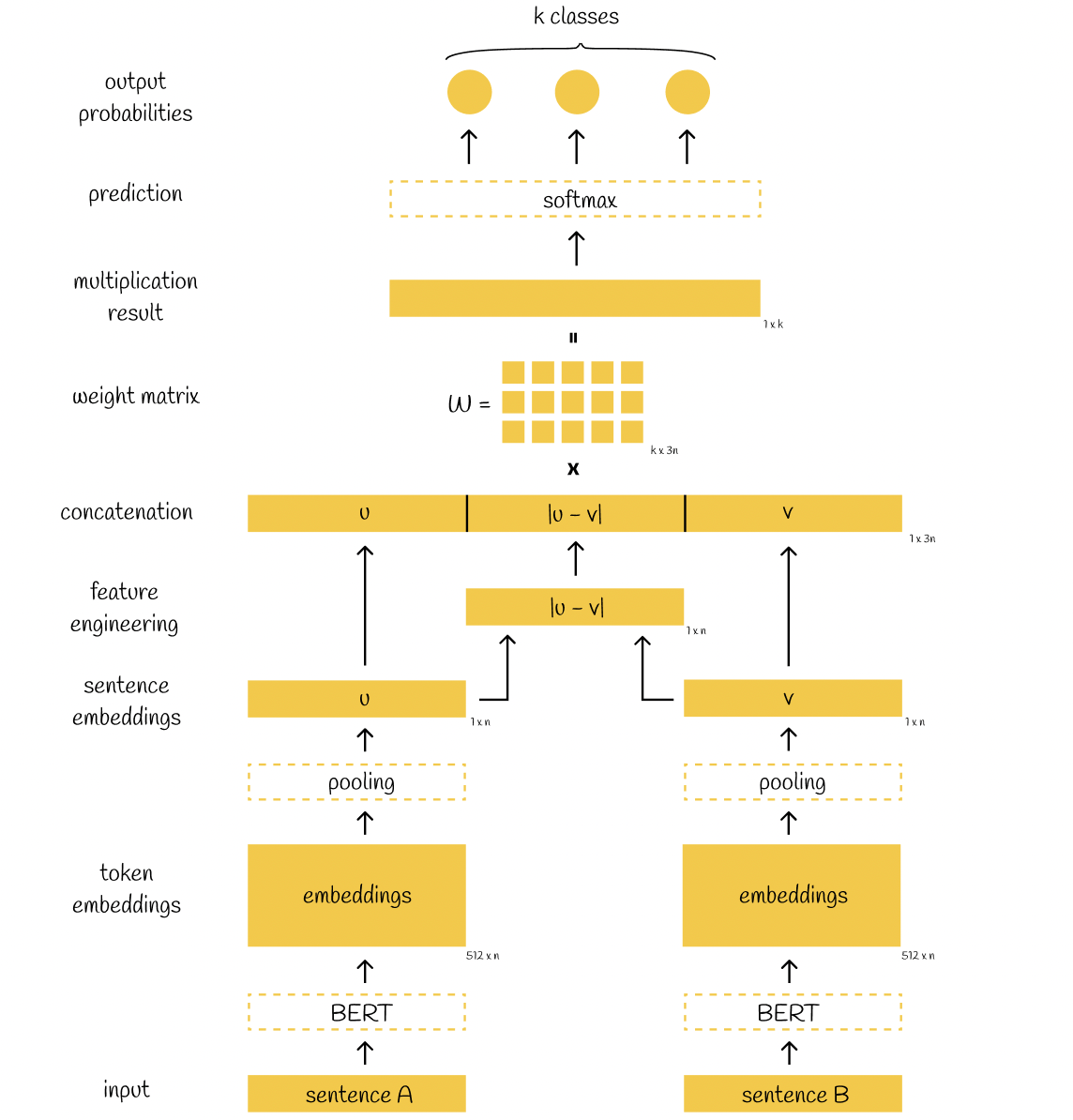
Sentence-BERT 的训练主要流程为:
- 输入:模型接收两个句子,句子 A 和句子 B。
- BERT 处理:每个句子通过 BERT 模型处理,生成对应的词元嵌入(例如维度为 512 x n,其中 n 是嵌入维度,512 是指 token 个数,BERT 模型在设计时,通常会将输入句子填充或截断到固定的最大长度 512)。
- 池化(Pooling):对词元嵌入进行池化操作(例如均值池化或最大池化),将每个句子的嵌入转换为固定大小的句子嵌入(维度为 1 x n)。句子 A 生成嵌入 ,句子 B 生成嵌入 。
- 特征工程:计算句子嵌入 和 的元素级差值 (主要是为了更好地捕捉两个句子之间的语义关系,特别是在需要比较句子相似性或关系的任务中),然后将 、 和 拼接成一个向量 (维度为 1 x 3 n)。
- 权重矩阵乘法:拼接后的向量与一个权重矩阵 (维度为 k x 3 n,其中 是类别数量)相乘,得到一个乘法结果(维度为 1 x k)。
- Softmax 层:乘法结果通过 softmax 层,生成 个类别的输出概率。
- 预测:根据最高的概率值,模型输出最终的预测结果,分为 个类别之一。
这种架构非常适合处理语义文本相似度等任务,能够高效地分析句子对之间的语义关系。在模型训练完成后,实际应用中通常只需使用编码器生成的句子嵌入,无需保留 softmax 分类层。分类任务在训练阶段的主要作用是作为监督信号,目的是学习出具有良好语义表达能力的句子表示。
Sentence-BERT(SBERT)最早由德国达姆施塔特工业大学(Technische Universität Darmstadt)的 UKP 实验室提出,用于生成更高质量的句子级别语义向量。它显著提升了语义文本相似度、语义搜索等任务的效果,因此迅速在自然语言处理社区中流行起来。
为方便开发者使用,UKP 实验室还发布了 SentenceTransformers 库,作为 SBERT 的官方实现,提供了简洁易用的 API 和丰富的预训练模型,覆盖了多种常见应用场景。如今,该库已由 Hugging Face 社区主力维护,并不断扩展支持,包括最新的嵌入模型和我们后续会介绍的 Reranker(重排序)模型等。
在 Hugging Face 社区里,Sentence Similarity 任务 Most likes 与 Most downloads 的都是 all-MiniLM-L6-v2 这个模型,不过这个模型只支持英语,下面会介绍北京智源研究所与 Jina.ai 这两家开发的多语言多任务文本嵌入模型。
jina-embeddings-v3
jina-embeddings-v3 在日常的 RAG 搭建中使用挺多的。
jina-embeddings-v3 是一种多语言多任务文本嵌入模型,专为各种 NLP 应用而设计。该模型基于 Jina-XLM-RoBERTa 架构,支持旋转位置嵌入,可处理多达 8192 个标记的长输入序列,相比于 all-MiniLM-L6-v2 几百 token 的最大输入长度,jina-embeddings-v3 将其扩展了 30 倍多,极大地提升了处理长文本的能力,使其能够应用于更广泛的场景,例如长文档的语义搜索、文本摘要等。此外,它还具有 5 个 LoRA 适配器,可高效生成特定任务的嵌入。注意力机制方面,jina-embeddings-v3 采用了 FlashAttention2 进一步提升性能并降低内存消耗。
长上文支持
jina-embeddings-v3 用 RoPE(Rotary Position Embeddings)替换了传统的绝对位置编码,将位置信息以旋转矩阵的方式融入自注意力机制中,从而支持更长的文本序列输入。RoPE 能够更好地捕捉长距离依赖关系,提升模型对长文本的处理能力。
训练过程中,模型先在 512 tokens 的短文本上训练,再在 8192 tokens 的长文本上继续训练,并相应调整 batch size。这种分阶段训练方式,确保模型既能处理短文本,也能适应超长文本输入。
LoRA Adapters
jina-embeddings-v3 采用 LoRA (Low-Rank Adaptation) Adapters,这是一种高效的参数微调方法。LoRA Adapters 是为特定下游任务(如检索、分类、聚类、文本匹配等)专门训练的小型可插拔模块。通过在主模型的部分层插入低秩矩阵,LoRA Adapters 能够在不改变主模型参数的情况下,快速适配并生成针对特定任务优化的文本嵌入。在 jina-embeddings-v3 中,主模型参数保持冻结,仅训练 LoRA Adapter,从而高效地为不同任务生成最优嵌入。
jina-embeddings-v3 针对四种明确界定的任务类型训练了五个不同的 LoRA 适配器:
| 任务类型 | 任务描述 |
|---|---|
| retrieval.passage | 检索任务中的文档嵌入 |
| retrieval.query | 检索任务中的查询嵌入 |
| separation | 聚类、可视化语料库 |
| classification | 文本分类 |
| text-matching | 语义相似度、对称检索、推荐、去重等 |

不同任务需要使用不同的 Adapter,是因为每类任务对文本嵌入的需求和判别标准不同,专用 Adapter 能针对性优化嵌入空间,从而显著提升各自任务的效果。比如检索通常是“查询-文档”非对称匹配,需要分别优化查询和文档的嵌入,使它们在向量空间中能正确对应;而分类需要嵌入能清晰区分不同类别,便于下游分类器(如逻辑回归)直接利用;聚类则要求同一组内的文本嵌入彼此接近,不同组间距离远,便于聚类算法分组。
用同一个嵌入空间同时服务所有任务,往往会出现“顾此失彼”,即某些任务表现好,另一些任务表现下降。通过为每个任务训练专属 LoRA Adapter,可以在不改变主模型参数的前提下,快速适配和优化不同任务。这样既保证了多任务的高性能,又避免了多模型部署的资源浪费。
Matryoshka Embeddings
jina-embeddings-v3 支持 Matryoshka 表示学习(Matryoshka Representation Learning,简称 MRL)技术,使得用户可以根据具体需求灵活调整嵌入向量的维度,从而在保持性能的同时优化存储和计算资源的使用。
Matryoshka 的灵感来源于俄罗斯套娃,其设计理念是将最重要的信息存储在嵌入向量的前部维度中,而将次要信息存储在后部维度中。 
这种结构允许在截断嵌入向量时,仍然保留足够的语义信息,从而在下游任务中表现良好。 Matryoshka 表示学习允许将高维嵌入向量(默认 1024 维)截断为较低维度(如 768、512、256、128、64、32 维),而性能损失最小。例如,在 64 维下仍可保留约 92% 的检索性能这种方法特别适用于对存储和计算资源有限的场景,如边缘设备部署、移动端应用或需要大规模索引的系统。
jina-embeddings-v3 默认输出 1024 维的嵌入向量。要使用 MRL 调整嵌入维度,可以在模型调用时指定所需的维度。
Multi-vector embeddings
Dense Embedding 表达一个长文档常常会丢失细节信息,特别是在长文本中用户的查询与文档某一小片段高度相关的情况下。而 multi-vector embedding(如 ColBERT)允许文档用多个向量表示(如按 token、句子、段落划分),提高 recall 和语义覆盖率。
ColBERT
ColBERT(Contextualized Late Interaction over BERT)是一种高效且有效的文本检索模型,主要特点如下:
延迟交互(Late Interaction):查询和文档分别用 BERT 独立编码,得到一组上下文相关的向量(embeddings)。在检索阶段,不是将查询和文档拼接后整体送入 BERT,而是先离线编码并存储文档向量,在线阶段仅对查询编码,在检索时构造查询-文档相似度矩阵,并用 MaxSim(对每个查询 token 取其与文档所有 token 的最大相似度,再求和)聚合得分。
这种“先分离再轻量交互”的策略,比传统跨编码器逐对评分节省了两个数量级的计算量,同时保留了词级对齐的精度。
细粒度相似度建模:ColBERT 把 BERT 输出的每个 token 向量通过线性变换压缩到 128 维左右,并为查询和文档分别独立编码,从而得到一组“上下文化的 token 级嵌入矩阵”。这种方式既保留了深度模型的表达能力,又能高效地进行大规模检索。
ColBERT 被称作 Multi-Vector Embedding 的原因,在于它并不像传统的语义检索模型那样,把整段文本压缩成 单个向量(single-vector embedding);而是保留了一组细粒度、上下文化的 token 级向量来共同表示同一份文本。
下图展示了神经信息检索中四种典型的查询-文档匹配范式,分别是:表示式相似(Representation-based)、交互式匹配(Query-Document Interaction)、全交互(All-to-all Interaction)、以及 ColBERT 提出的延迟交互(Late Interaction),它们在编码和匹配方式上各有不同。
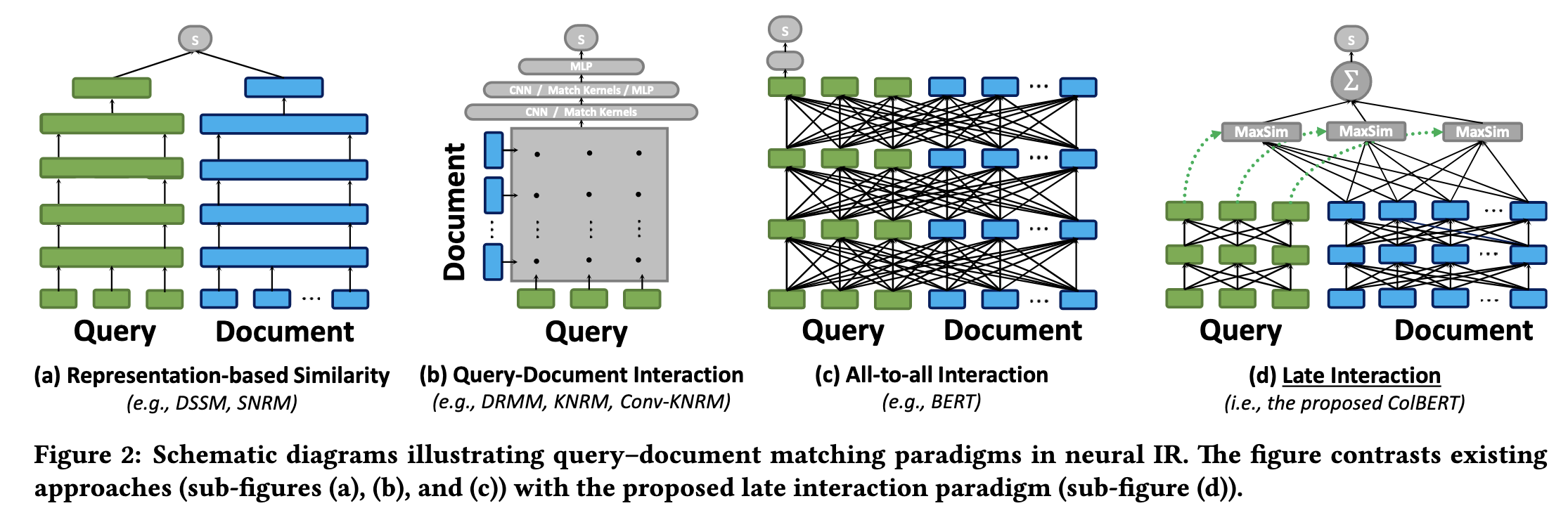
Representation-based 的方法基于表征的排序器,Query 与 Document 各自独立地整段池化成 1 个嵌入向量,然后用一个简单的相似度函数(如点积或余弦相似度)计算两者的相关性;该范式可以提前离线计算文档向量,检索速度快,但是只用单一向量表达全部语义,难以捕捉细粒度的词级匹配关系。
NOTE
DSSM 这种模型结构在推荐系统中被广泛借鉴,称为双塔模型(Two-Tower Model),即用户塔和物品塔分别编码用户和物品,在推荐系统中的召回环节很流行。先离线计算并存储所有物品的嵌入,在线时只需将用户特征编码为向量,与物品向量做相似度检索(如最近邻搜索),即可高效召回候选物品。
Query-Document Interaction 的方式不直接将查询和文档编码成单一向量,而是先分别编码成词级向量,然后构建一个交互矩阵,反映查询和文档每个词之间的相似度。再用神经网络(如 CNN、MLP、核池化等)对交互矩阵进行建模,输出相关性分数。能捕捉词与词之间的细粒度关系,效果好,但是每次检索都要在线计算交互矩阵,效率较低,难以离线预处理。
All-to-all Interaction 的方式将查询和文档拼接成一个序列,一起输入到 BERT 这类深度模型中,模型内部通过多层 Transformer 进行全局交互,输出相关性分数。该方法表达能力最强,能捕捉复杂的上下文和交互关系,但是计算量极大,无法离线预处理,检索效率低。
后面会讲到的 Cross-Encoder Reranker,就是典型的全交互(All-to-all Interaction)模型,能实现最细致的语义匹配,但计算成本很高,无法作为这一阶段进行大面积检索,一般用于第二阶段的精细化重新排序。
最后就是 ColBERT 的延迟交互的方式,兼顾了表达能力和效率。文档向量可离线预计算,查询时只需高效的向量操作,支持大规模检索,比单向量方法存储需求大,但远低于全交互方法的计算量。
接下来让我们了解下 ColBERT 中关键的 MaxSim 是怎么操作的。
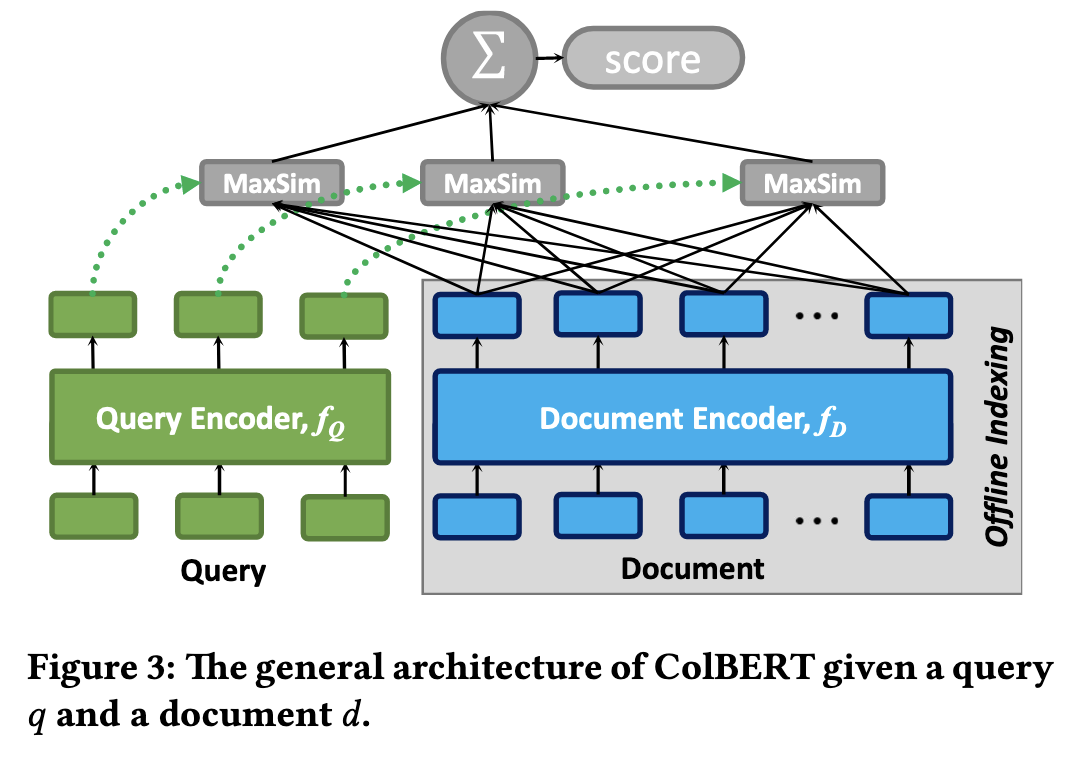
BERT 编码:
- 查询 q 被分词成
[q₁, q₂, … qₙ];文档 d 被分词成[d₁, d₂, … dₘ]。 - 经过同一个 BERT(或兼容模型)后,每个 token 得到一个 d-维向量:
计算两两相似度矩阵: 使用内积(或余弦)计算所有查询-文档 token 对:
MaxSim(Late Interaction): 对于每个查询 token i,只保留它与文档中最相似 token 的得分:
累加得到整体相关性:
核心直觉:每个查询词“挑”出文档里与自己最像的那一个词来贡献分数,所以 MaxSim 让匹配更加“细颗粒”、且只关心最强匹配位置,避免整句聚合时信息被稀释。
一个简单的例子:
查询 = “apple iphone” 文档 = “iphone battery life”
| token | 向量 |
|---|---|
| apple | (1.0, 0.0) |
| iphone | (0.8, 0.6) |
| battery | (0.0, 1.0) |
| life | (0.0, 0.8) |
相似度矩阵 (用点积;四舍五入到 2 位小数):
| iphone | battery | life | |
|---|---|---|---|
| apple | 0.80 | 0.00 | 0.00 |
| iphone | 1.00 | 0.60 | 0.48 |
取 MaxSim:
| 查询 token | 3 个文档 token 中最大值 |
|---|---|
| apple | 0.80 |
| iphone | 1.00 |
累加得到文档的最终分数:
如果把文档替换成“fresh apple pie”,能计算出 “iphone” 没有匹配(得分≈0),整体分就会明显下降——这体现了 MaxSim 在粒度上的判别力:每个查询词都必须在文档里找到强匹配,才能拿到高相关性。
bge-m3
bge-m3 是一个由 BAAI(北京智源研究所)开发的先进文本嵌入模型。该模型集成了多语言性(Multi-Linguality)、多粒度性(Multi-Granularity)和多功能性(Multi-Functionality)三大特性,旨在为搜索、问答系统、RAG(检索增强生成)等任务提供高效的文本嵌入解决方案。该模型一大特点是其直接能输出 Spare、Dense 和 Multi-vector 3 种类型的 Embedding,因此放在该节进行统一介绍。
bge-m3 支持超过 100 种语言,具备强大的多语言和跨语言检索能力。
模型能够处理从短句到长达 8192 个 token 的长文档,支持句子、段落、篇章等不同粒度的文本输入,满足多样化的文本处理需求。
bge-m3 集成了三种检索功能:
- 稠密检索(Dense Retrieval):不同于 Sentence-BERT,m3 通过自知识蒸馏(self-knowledge distillation)技术,利用 [CLS] 标记输出的 Dense Embedding 进行语义匹配,适合语义搜索任务。
- 稀疏检索(Sparse Retrieval): 基于每个 token 的嵌入 Embedding 构成 Spare Embedding。
- 多向量检索(Multi-Vector Retrieval):多个 token 级别的嵌入向量也可以构成类似 ColBERT 那样的 Multi-Vector Embedding,提升检索的细粒度匹配能力。
bge-m3 把每个 token 的隐藏向量直接映射成一个可学习的“词权重”,从而得到一个超稀疏、可倒排索引的向量;随后用查询-文档共有词项的权重乘积求和来打分。这让模型在生成稠密向量的同时,零额外成本得到类似 BM25 的精确匹配能力,并可与 Dense / ColBERT 分数加权融合。
得益于嵌入模型的多功能性,检索过程可以采用混合多种嵌入向量的方式进行。但这些检索方式的训练目标可能互相冲突,直接多目标训练会影响嵌入质量,那如何在训练的时候集成多种检索向量?
bge-m3 提出了自知识蒸馏(Self-Knowledge Distillation, SKD)框架,该框架将不同检索方式的相关性得分(如密集得分、稀疏得分、多向量得分)集成为更强的“教师信号”。这种集成方式借鉴了集成学习(ensemble learning)的思想,认为多种异构预测器的组合能提供更准确的相关性判断。
训练时,分别计算三种检索方式的得分(sdense, slex, smul),然后将三种得分相加,得到集成得分 ,作为“教师”。每种检索方式的损失函数都用 作为软标签进行蒸馏,鼓励各自的预测向集成结果靠拢。最终损失函数是原始损失和蒸馏损失的加权和。
训练流程分为两个阶段:第一阶段使用大规模无监督数据进行预训练,仅训练密集检索;第二阶段使用自知识蒸馏联合训练三种检索功能,以提升整体表现。
这种方法能有效缓解多目标训练的冲突,使三种检索方式相互促进,提升模型在多功能检索任务中的表现。
Hybrid retrieval
至此介绍完了 BM25 与 3 种 Embedding 的检索策略,这几种检索方法常常作为第一阶段检索(也称为召回)。然而,单一的检索策略往往难以覆盖所有类型的查询,例如,BM25 擅长处理字面匹配的查询,而 Embedding 检索则更适合语义相关的查询。为了结合不同检索策略的优势,弥补彼此的不足,我们可以利用了各种搜索策略的优势,这样的混合检索(Hybrid retrieval)具有更高的准确性和更强的泛化能力。
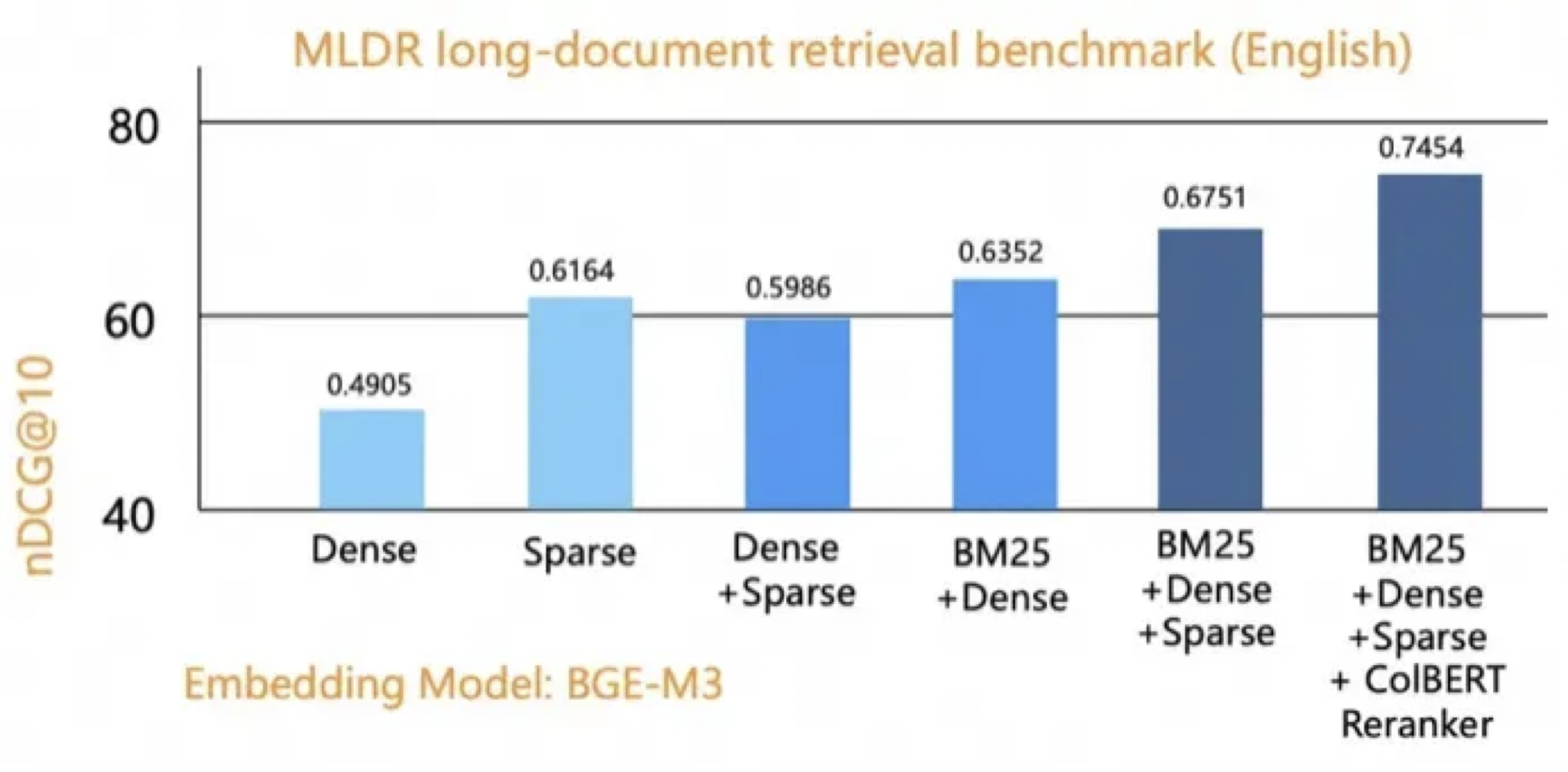
Hybrid Search 的核心思想是将多个检索通道的结果进行融合,从而获得更全面、更准确的检索结果。常见的融合策略包括倒数排序融合 (Reciprocal Rank Fusion, RRF) 和加权融合 (Weighted Fusion)。
RRF 是一种简单有效且鲁棒性强的融合策略,它根据每个文档在不同检索通道中的排名来计算最终得分。具体来说,文档 在检索通道 中的排名为 ,则其 RRF 得分为:
其中, 是检索通道的数量, 是一个常数,通常设置为 60。
示例代码如下:
def rrf_fusion(rankings, k=60):
"""
RRF融合排序算法
Args:
rankings: 多个排序列表,每个列表包含文档ID
k: RRF参数,默认为60
Returns:
融合后的排序结果
"""
# 存储每个文档的RRF分数
document_scores = {}
# 计算每个文档在所有排序中的RRF分数
for ranking in rankings:
for rank, doc_id in enumerate(ranking):
# RRF公式: 1 / (k + rank),其中rank从0开始
score = 1 / (k + rank + 1) # rank+1是因为排名从1开始计算
if doc_id in document_scores:
document_scores[doc_id] += score
else:
document_scores[doc_id] = score
# 按分数降序排列
fused_ranking = sorted(document_scores.items(), key=lambda x: x[1], reverse=True)
return fused_ranking
举个例子,假设有以下输入排序:
输入排序: 排序1:A, B, C 排序2:B, C, A
RRF分数计算(k=60):
文档A: 排序1第1位:1/(60+1) = 1/61 ≈ 0.0164 排序2第3位:1/(60+3) = 1/63 ≈ 0.0159 总分:0.0323
文档B: 排序1第2位:1/(60+2) = 1/62 ≈ 0.0161 排序2第1位:1/(60+1) = 1/61 ≈ 0.0164 总分:0.0325
文档C: 排序1第3位:1/(60+3) = 1/63 ≈ 0.0159 排序2第2位:1/(60+2) = 1/62 ≈ 0.0161 总分:0.0320
融合结果:
- B (0.0325)
- A (0.0323)
- C (0.0320)
RRF通过倒数排名加权,让文档B从两个排序的综合表现中胜出。
另外一种方法是加权融合 (Weighted Fusion):为每个检索通道分配一个权重,然后将各个通道的得分进行加权求和。该方法很直观,不过权重的选择需要基于经验或者通过学习得到。
Reranker
在前面的章节中,我们深入探讨了从传统的 BM25 到现代的 Embedding 技术,再到hybrid retrieval 的演进过程。然而,即使是最先进的检索方法,在面对复杂的语义理解任务时仍然存在局限性。这就是为什么我们需要 Reranker——提升最终排序精度的关键一步,它能够对初步检索的结果进行精细化的重新排序,显著提升最终的检索质量,特别是在 RAG 场景中,优质的输入文档直接决定了生成内容的准确性。
与前面提到的 BM25 关键词匹配和 Embedding 向量相似度计算不同,Reranker 采用了更加精细的交叉注意力机制,能够深入理解 query 和 document 之间的复杂语义关系。
想象这样一个场景:当你搜索"如何提高深度学习模型的泛化能力"时,初始检索可能会返回包含"深度学习"、"模型"、"泛化"等关键词的文档。但是,哪些文档真正回答了"如何提高"这个核心问题?哪些只是泛泛而谈?这就需要 Reranker 来做更精准的判断。
传统的 Embedding 检索虽然能够捕捉语义相似性,但它是基于独立编码的向量相似度计算,缺乏 query 和 document 之间的深度交互。而 Reranker 的核心优势在于交叉注意力机制(Cross-Encoder )——它会同时考虑 query 和 document 的内容,让两者在模型内部进行充分的信息交互(类似于 ColBERT 那一小节提到的 All-to-all Interaction)。
NOTE
之前提到的 ColBERT 支持高效大规模向量检索,也能作为高质量的 reranker,但效果可能比 Cross-Encoder 差。实际应用中,可以根据需求选择其中一种或结合使用。
具体来说,Reranker 会将 query 和 document 拼接后输入到预训练的语言模型中,通过自注意力机制让 query 中的每个 token 都能"看到" document 中的所有 token,反之亦然。这种密集的交互使得模型能够理解更复杂的语义关系,比如:
- 因果关系:query问"为什么",document是否真的解释了原因
- 对比关系:query涉及比较,document是否提供了对比信息
- 时序关系:query关注过程,document是否描述了步骤顺序
Cross-Encoder 是目前 Reranker 中使用最广泛的一种架构,核心思想是在同一个 Transformer 中对 query 和 document 进行联合建模,从而学习出它们之间的语义交互关系。相比于 Bi-Encoder(双塔模型)将 query 和 document 分别编码为向量后计算余弦相似度,Cross-Encoder 会在同一个模型中处理这对输入,更加细致地刻画两者的关系。
Bi-Encoder(双塔架构):
Query → Encoder A → Query Vector
Document → Encoder B → Document Vector
Similarity = cosine(Query Vector, Document Vector)
在 Bi-Encoder 中,query 和 document 被独立编码成向量,然后通过余弦相似度等方法计算相关性。这就是我们前面章节中讨论的 Dense Embedding 方法。
Cross-Encoder(交叉编码架构):
[CLS] Query [SEP] Document [SEP] → Transformer → Relevance Score
[CLS] 是分类任务的特殊标记,其最终表示用于相关性判断,[SEP] 是分隔符,明确区分 query 和 document 的边界。Cross-Encoder 将 query 和 document 拼接成一个序列,一起输入到 Transformer 模型中,让两者在模型内部进行充分的信息交互。
Cross-Encoder 使用输出的 [CLS] token(或做 pooling 后的表示)作为整个输入对的表示,然后通过一个线性层输出一个相关性得分(通常是一个实数或概率),表示这篇文档与查询是否相关,或者有多相关。
由于每次都要将一对 [query, document] 送入 Transformer 编码一遍,Cross-Encoder 的计算成本极高。如果要重排 100 条候选文档,就要进行 100 次前向传播。因此只能用于最后一步的 reranking,而不能用于大规模召回。
早期的 Reranker 主要基于 BERT 架构,如 MonoT5 和 RankT5。这些模型通过在大规模查询-文档对上进行训练,学会了判断文档与查询的相关性。虽然效果不错,但推理速度相对较慢。
随着技术发展,出现了专门为 reranking 任务优化的模型,常见的 reranker 模型包括 Cohere Rerank(在线闭源服务,英文模型)、BAAI 开源的 bge-reranker 系列(如 bge-reranker-v2-m3 和 bge-reranker-base,多语言,支持本地部署且性能较好)、以及 Jina Reranker(jina-reranker-v2-base-multilingual) 等。
小结
回顾整个 RAG 检索技术的探索历程:
- BM25 奠定了关键词检索的基础,在精确匹配场景下仍然无可替代;
- Sparse Embedding(SPLADE) 将稀疏检索推向了新的高度,兼顾了可解释性和效果;
- Dense Embedding 开启了语义检索的新纪元,让机器真正理解了文本含义;
- Multi-vector embeddings 进一步提升了表示能力,处理复杂文档结构;
- Hybrid 检索融合了多种技术的优势,在实际场景中表现出色;
- Reranker 作为最后的精排环节,确保输入到 LLM 上下文的最终结果是高度相关的。
在实际项目中,最佳实践往往是这些技术的有机组合:
- 轻量级场景:BM25 + Dense Embedding
- 标准场景:Hybrid retrieval(BM25 + Dense Embedding)
- 高精度场景:Hybrid retrieval + Reranker
- 特殊领域:基于 SPLADE 的可解释性检索 + 专业领域的 Reranker
未来,随着大语言模型的发展,我们可能会看到更多端到端的检索方案,但理解这些基础技术的原理和适用场景,仍然是构建高质量 RAG 系统的关键。毕竟,技术的演进是渐进的,而工程实践中的权衡永远存在。
天下没有免费的午餐,永远没有最好的检索策略与模型,你很难做到既要又要,选择合适的技术组合,不仅要看效果,更要看是否适合你的具体场景、资源约束和长期维护能力。

