- Published on
Attention 内存优化管理:KV 缓存量化、FlashAttention 和 vLLM 的实践指南
- Authors

- Name
- Jason Huang
- @zesenhhh
Table of Contents
内存都缓存了什么
Transformer 训练和推理时的内存占用有一些不同,训练过程中内存需要存储模型参数、Query 矩阵、Key 矩阵、Value 矩阵、梯度、激活值等,内存一般比推理过程占用大,而推理时只需要存储模型参数等,不用存储梯度和激活值。
但是,为了加速计算,推理时通常会使用 kv cache(键值缓存),即保存前面已经计算过的 Key(k)和 Value(v)矩阵。这样在生成新 token 时,不需要重复计算前面所有 token 的 k 和 v,只需要将新生成的 token 对应的 Query(q) 与之前缓存的 kv 进行注意力分数计算:
这极大地减少了计算量,提高了推理速度,尤其是在长序列生成任务中,比如文本生成或对话任务。
加载模型进行推理时,GPU 的内存需要加载模型的全部参数,模型加载到内存中是必不可少的。为了在消费级 GPU 上运行大模型,可以借助模型量化技术来显著降低内存需求。例如,使用 Ollama 下载经过量化的开源模型,即使牺牲了部分模型性能,依然可以在个人电脑上运行模型。
第二大常驻内存的便是 kv cache。

键值缓存或 KV 缓存是一种优化自回归模型生成速度的重要方法。自回归模型需要逐个预测下一个生成词元(token),这一过程可能会很慢,因为模型一次只能生成一个词元,且每个新预测都依赖于先前的生成。也就是说,要预测第 1000 个生成词元,你需要综合前 999 个词元的信息,模型通过对这些词元的表征使用矩阵乘法来完成对上文信息的抽取。等到要预测第 1001 个词元时,你仍然需要前 999 个词元的相同信息,同时还还需要第 1000 个词元的信息。这就是键值缓存的用武之地,其存储了先前词元的计算结果以便在后续生成中重用,而无需重新计算。
具体来讲,键值缓存充当自回归生成模型的内存库,模型把先前词元的自注意力层算得的键值对存于此处。在 transformer 架构中,自注意力层通过将查询与键相乘以计算注意力分数,并由此生成值向量的加权矩阵。存储了这些信息后,模型无需冗余计算,而仅需直接从缓存中检索先前词元的键和值。下图直观地解释了键值缓存功能,当计算第 K+1 个词元的注意力分数时,我们不需要重新计算所有先前词元的键和值,而仅需从缓存中取出它们并串接至当前向量。该做法可以让文本生成更快、更高效。
在生成任务的推理阶段,缓存的 K 和 V 矩阵主要来自带有 attention 机制的每个 Transformer blocks(encoder 块或者 decoder 块),也可以称之为层数。回忆一下 Transformer 的模型结构,就是来自下图的橙色 encoder 与紫色 decoder:
![]()
类 GPT 大模型都是 decoder-only 的架构,因此所有的层都是 decoder 块。当用 7 B Llama-3 模型处理 10000 个词元的输入时,所需要存储 kv cache 的内存大致为 2 * 2 * 层数(Transformer blocks) * head数 * 每个head的维度,其中第一个 2 表示键和值,第二个 2 是我们需要的字节数 (假设模型加载精度为 float16 )。因此,如果上下文长度为 10000 词元,仅键值缓存我们就要约 2 * 2 * 32 * 32 * 128 * 10000 ≈ 5GB 的内存占用。
KV 缓存量化
如同模型可以将其权重参数从 fp16 转为 int 等类型一样进行量化,kv cache 也一样可以进行量化。KV 缓存量化可在最小化对生成质量的影响的条件下,减少模型在长文本生成场景下的内存使用量,从而在内存效率和生成速度之间提供可定制的权衡。
当我们对模型中的 KV 缓存进行量化时,内存需求减少,但生成速度有时会因此降低。尽管将缓存量化为 int4 可以节省大约 2.5 倍的内存,生成速度却可能随着批量大小的增加而减慢。因此,用户必须权衡利弊:在实际用例中,是否值得牺牲一些速度来换取内存效率的显著提升,这取决于需求的优先级排序。
如何在 🤗 Transformers 中使用量化 KV 缓存?
首先 pip install quanto 安装依赖。
然后在调用 generate 时传入 cache_implementation="quantized" 并以字典格式在缓存配置中设置量化参数,cache_config 选择使用 quanto 作为后端来执行量化,目前的实现仅支持 int2 和 int4 类型。无论使用的是 CPU/GPU/MPS (苹果芯片),都可以量化并运行模型。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.float16, device_map="cuda:0")
inputs = tokenizer("I like rock music because", return_tensors="pt").to(model.device)
out = model.generate(**inputs, do_sample=False, max_new_tokens=20, cache_implementation="quantized", cache_config={"backend": "quanto", "nbits": 4})
print(tokenizer.batch_decode(out, skip_special_tokens=True)[0])
FlashAttention
如果不想对 kv cache 进行量化,避免牺牲模型性能与拖慢生成速度,则训练与推理过程中可以采用 FlashAttention。
FlashAttention 是一种高效的注意力计算方法,旨在解决 Transformer 模型在处理长序列时的计算效率和内存消耗问题。==其核心思想是通过在 GPU 显存中分块执行注意力计算,减少显存读写操作,提升计算效率并降低显存占用==。
该机制通过考虑 GPU 内存层次结构中的数据读写操作,采用了基于磁盘的数据存储(HBM)和快速的 GPU 片上存储器(SRAM)之间的数据块传输和计算方法。通过重新组织注意力计算过程,避免了在 HBM 中读写大型注意力矩阵,从而减少了内存访问次数,提高了计算效率。
NOTE
GPU 中的 HBM(High Bandwidth Memory,高带宽内存)和 SRAM(Static Random Access Memory,静态随机存取存储器)是两种不同类型的内存,各自有不同的特性和用途:
- HBM 是一种专为高性能计算和图形处理设计的内存类型,旨在提供高带宽和较低的功耗。HBM 常用于需要大量数据访问的任务,如图形处理、大规模矩阵运算和 AI 模型训练。
- SRAM 是一种速度极快的存储器,用于存储小块数据。在 GPU 中,SRAM 主要作为缓存(如寄存器文件、共享内存和缓存),用于快速访问频繁使用的数据。例如在图中 FlashAttention 的计算中,将关键的计算块(如小规模矩阵)存放在 SRAM 中,减少频繁的数据传输,提升计算速度。
主要工作原理:
- 分块计算:传统注意力计算会将整个注意力矩阵 (N×N) 存入 GPU 内存(HBM),这对长序列来说非常消耗内存,FlashAttention 将输入分块,每次只加载一小块数据到更快的 SRAM 中进行计算;
- 降低显存读写:在 GPU 的 HBM 中,每次的显存读写操作相对较慢,FlashAttention 尽可能地减少了显存的读写频率。在分块计算过程中,将 Q、K、V 的小块加载到显存中计算后,马上释放,避免整个矩阵常驻显存,从而减少了显存的读写量和占用;
- 内联 softmax:传统的 softmax 操作在完整计算 后才进行,而 FlashAttention 则在分块内即时执行 softmax,进一步减少计算开销,通过重组计算顺序,减少了从 HBM 读取中间注意力矩阵。
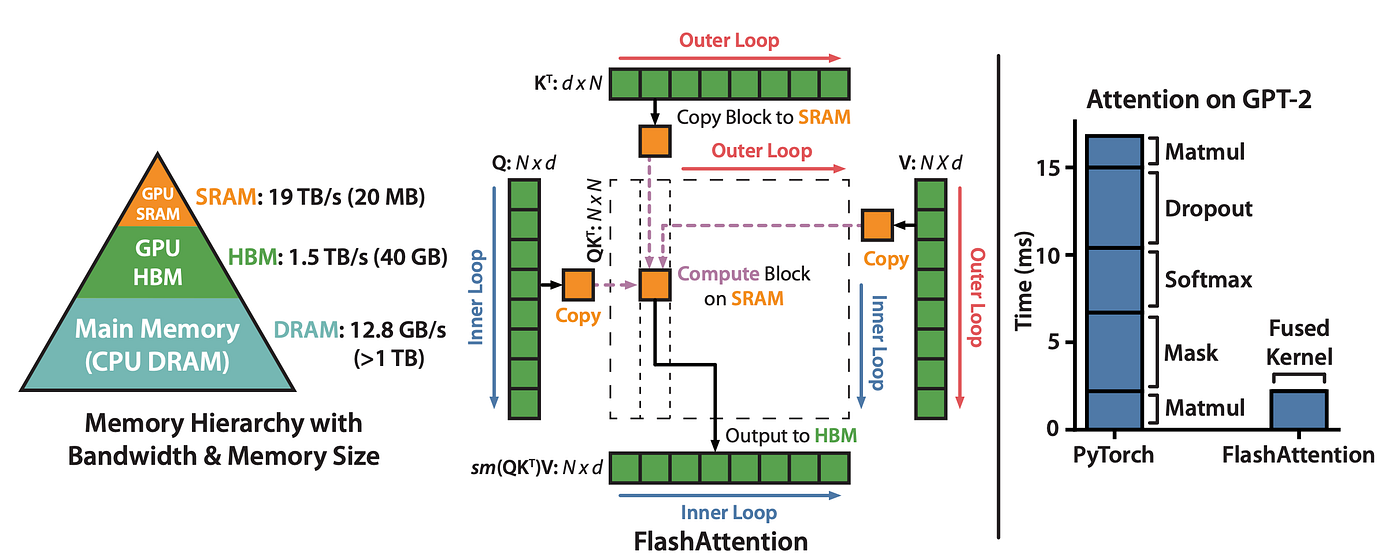
FlashAttention-2 在性能上比 FlashAttention 有了显著提升,达到了 NVIDIA A100 GPU 理论计算性能的 50-73%,接近 GEMM(通用矩阵乘法,通常是 GPU 上最高效的运算之一)的效率。在端到端训练 GPT 风格模型时,FlashAttention-2 能在每块 A100 GPU 上实现 225 TFLOPs/s 的速度,相当于 A100 理论性能的 72%。。
NOTE
PyTorch 2.2(Beta) 通过与 FlashAttention-v2 集成,将 scaled_dot_product_attention 的性能提高了 ~2倍。
如何在 🤗 Transformers 模型推理中使用 FlashAttention-2?
英伟达用户首先确保 CUDA 版本 11.6 以上,FlashAttention-2 兼容 Ampere 和 Ada 架构的 GPU,包括 A100, RTX 3090, RTX 4090, H100 等型号,然后安装依赖:
pip install flash-attn --no-build-isolation
当前支持的数据类型为 fp16 和 bf16(bf16 需要使用 Ampere、Ada 或 Hopper GPU)。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
FlashAttention-2 可以与量化等其他优化技术相结合,进一步加快推理速度。例如,您可以将 FlashAttention-2 与 8 位或 4 位量化相结合:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
# load in 8bit
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_8bit=True,
attn_implementation="flash_attention_2",
)
# load in 4bit
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
attn_implementation="flash_attention_2",
)
PagedAttention(vLLM)
FlashAttention 关注计算效率,显著提升了每次注意力分数的计算效率与 GPU 的使用效率。而在实际生产环境中部署模型并给用户提供高吞吐服务时,普通的系统并不能很好的满足生产需求,因为每个请求的 kv cache 内存很大,并且会动态增长和收缩。
尽管把用户的每次请求打包分批(Batching)以提升模型推理的效率,现有的 LLM 服务系统仍无法有效地管理 kv cache。这主要是因为它们将用户请求的 kv cache 存储在连续的内存空间中,因为大多数深度学习框架要求将张量存储在连续的内存中。
现有系统在处理 kv cache 时存在的 3 个主要内存问题:

- 预留浪费 (Reserved):为将来可能的 token 预留的空间,这些空间被保留但暂未使用,其他请求无法使用这些预留空间;
- 内部内存碎片化问题(internal memory fragmentation):系统会为每个请求预先分配一块连续的内存空间,大小基于最大可能长度(比如2048个token),但实际请求长度往往远小于最大长度,这导致预分配的内存有大量空间被浪费。
- 外部内存碎片化问题(external memory fragmentation):不同内存块之间的零散空闲空间,虽然总空闲空间足够,但因不连续而难以使用。
在现有系统中,只有 20.4%-38.2% 的 kv cache 内存被实际用于存储 token 状态,这意味着有超过 60% 的内存空间被浪费了。
想象一个停车场系统:
- 预留浪费:某人预约了 10 个车位,但目前只停了 3 辆车,剩余 7 个位置被预留着,其他人不能使用这些空位。
- 内部碎片化:分配了一个大车位,停了一辆小车,车位内剩余的空间无法被利用。
- 外部内存碎片化:停车场中散布着单个的空位,虽然总空位数量够停一辆大巴,但因为不连续,大巴无法停放。
为了解决上述问题,vLLM 采用集中式调度器来协调分布式 GPU 工作节点的执行。借助 PagedAttention,KV 缓存管理器以分页的方式高效管理 KV 缓存。具体而言,KV 缓存管理器根据集中式调度器的指令管理 GPU 工作节点上的物理 KV 缓存内存。
整个 vLLM 的系统设计如下图:

主要是以下几个关键部分:
- PagedAttention:与传统的注意力算法不同,==PagedAttention 允许在非连续的内存空间中存储连续的键和值==。具体来说,PagedAttention 将每个序列的 kv cache 划分为 kv 块。每个区块都包含固定数量的 Token 的 key 和 value 向量。
- KV Cache Manager:==vLLM 借鉴了操作系统虚拟内存的核心思想,将其应用到了LLM 服务中的 KV缓存管理==。在操作系统中,内存会被分割成固定大小的页面(pages),并且将用户程序的逻辑页面映射到物理页面上。虽然逻辑上页面是连续的,但它们可以对应到物理内存中非连续的页面。==KV 缓存管理器支持在 GPU 和 CPU 之间交换物理块,以便在 GPU 内存不足时,可以将不常用的块移动到 CPU 内存中。==
- 支持不同 LLM 多种解码方式:不同的解码方式对应不同的 KV 缓存管理策略,vLLM 系统支持多种解码方法,包括贪心解码、并行采样(Parallel sampling)和束搜索(Beam Search)等。
- 处理分布式内存:由于许多大型语言模型的参数规模超出了单个 GPU 的容量,因此需要将它们在分布式 GPU 上进行分区,并通过模型并行的方式执行。vLLM 通过在 Transformer 架构中支持广泛使用的 Megatron-LM 风格张量模型并行策略,使得 KV 缓存管理器也具备处理分布式内存的能力。
NOTE
Megatron-LM 是一种用于训练大型语言模型的高效并行技术。它采用了张量模型并行的方式,将整个模型的参数分割和分布在多个GPU上进行训练。
如何使用 vLLM?
vLLM 是一个 Python 库,还包含预编译的 C++ 和 CUDA (12.1) 二进制文件。可以把它当作一个专注于模型推理的框架,可以将使用 vLLM 在自己的机器上部署自己的模型,接收用户的请求并返回模型的输出,当前 vLLM 支持绝大多数开源的 LLM。
对系统要求如下:
- OS: Linux
- Python: 3.8 - 3.12
- GPU: compute capability 7.0 or higher (e.g., V100, T4, RTX20xx, RTX 40 xx,A100, L4, H100 等,消费级 GPU 完全没问题)
# (Recommended) Create a new conda environment.
conda create -n myenv python=3.10 -y
conda activate myenv
# Install vLLM with CUDA 12.1.
pip install vllm
推荐使用 cuda 12.1,并且用 pip 安装,不推荐用 conda 安装 vLLM,这是因为 pip 可以使用独立的库包(如 NCCL)来安装 torch,而 conda 则使用静态链接的 NCCL 来安装 torch。当 vLLM 尝试使用 NCCL 时,这可能会导致问题。用 conda 来创建虚拟环境没问题。
安装好 vLLM 后,我日常一般用 vLLM 提供一个 HTTP 服务器,可实现 OpenAI 标准的的 API,这样方便在 GPT-4o 的调用与自己的模型间切换。
首先,先在 Linux 的终端上执行以下命令启动 vLLM 服务,同时指定下载好的模型,比如运行 Qwen 2.5-7B 模型:
vllm serve /models/Qwen--Qwen2.5-7B-Instruct --dtype auto --api-key token-abc123 --tensor-parallel-size 2
上述命令将在后台运行指定的 LLM,/models/Qwen--Qwen2.5-7B-Instruct 是本地自己存放模型的目录,同时设置数据类型 dtype 为自动,还需要自己设置请求的 api-key,另外 tensor-parallel-size 可以设置运行在几张 GPU 上。
最后,在自己的代码中请求 vLLM:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="token-abc123",
)
completion = client.chat.completions.create(
model="/models/Qwen--Qwen2.5-7B-Instruct",
messages=[
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)
参考
- 用 KV 缓存量化解锁长文本生成
- GitHub - Dao-AILab/flash-attention: Fast and memory-efficient exact attention
- HuggingFace GPU inference 文档
- vLLM 文档
- Efficient Memory Management for Large Language Model Serving with PagedAttention
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
限于篇幅与精力,本文没过多涉及 Transformer 变体在训练阶段的内存优化,感兴趣的可以了解下 Reformer 和 Longformer:
此外还有很多其他的模型架构与内存管理优化方法,欢迎有深入了解的朋友留言补充。

