- Published on
MiniMax-M3:MSA 技术报告速读
- Authors

- Name
- Jason Huang
- @zesenhhh
Table of Contents
M3 背后的 MiniMax Sparse Attention(MSA)不追求机制新颖,而是用奥卡姆剃刀的思路,把「块级 top-k 稀疏注意力」这套已知方法,在 109B / 3T token 从头训练加自研 kernel 上做到了与全注意力持平、并真正落地生产。
背景:MiniMax 注意力的「试探—回撤—再出发」
MiniMax 三代注意力机制的演进并非线性递进,而是试探、回撤、再出击的曲折路径——这正是 M 3 选择稀疏注意力的关键背景。
MiniMax-01 / M1(2025)——押注线性:核心是 Lightning Attention(线性注意力的一种面向 I/O 优化的高效实现),采用「以线性为主」的混合设计:每 7 个线性块配 1 个 softmax 全注意力块,原生支持百万级上下文,让强化学习训练在 512 张 H800 上三周跑完。这是激进的一步。
M2(2025.10)——意外回撤到全注意力:M2 没有继承 M1 的 Lightning Attention,反而退回了纯全注意力。官方博客《Why Did M2 End Up as a Full Attention Model?》说得异常直接——高效注意力还没到可投产的程度。核心教训是「没有免费午餐」:混合注意力在已经饱和的老一批评测集(MMLU / BBH / LongBench)上看着和全注意力一样好,但规模一上去,复杂多跳推理就露馅了;而且全注意力背靠多年的 kernel 与推理工程积累,线性、稀疏的工程栈当时还不够成熟。
M3(2026.06)——再出发,切到稀疏:M3 用 MSA 把效率重新捡了回来。
问题与路线选择
超长上下文(几十万到上百万 token)已经是智能体工作流、仓库级代码推理、长期记忆的刚需,但 softmax 注意力的 O(N²) 成本让它在部署规模上难以承受。
解决思路目前分三条路:
- 混合架构:用线性注意力或滑窗替换一部分 softmax 层(MiniMax M1、Qwen 等);
- 改造注意力本身:MLA 把 KV 压进低维隐空间(DeepSeek);
- 稀疏化 softmax:保留 softmax 的表达力,只让每个 query 关注一小撮 KV(NSA / MoBA / DSA / MSA)。
MSA 明确选了第三条,而且选得很「保守」——建在标准 GQA 上、不压缩 KV、块级选择。这背后是一个清晰的产品判断:最大化复用现有软硬件基础设施,让它能在尽可能多的 GPU 上高效跑起来。M2 当时坚持了全注意力,M3 是第一次正式切到稀疏。
核心机制:两个分支,先选后算
MSA 把稀疏注意力拆成经典的两阶段——「先选哪些 KV」加「在选中的 KV 上做注意力」。
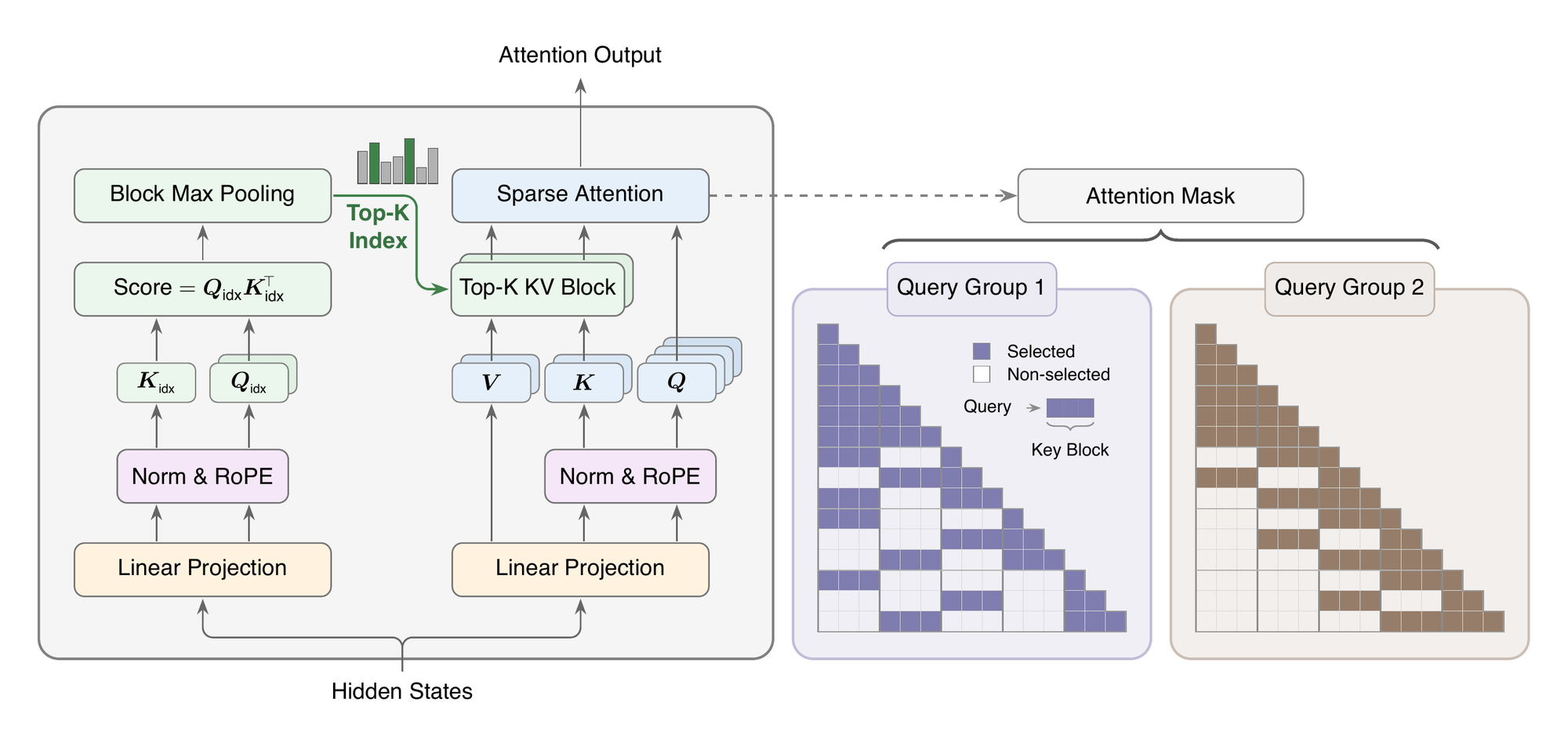
索引分支(Index Branch,极轻)
只给标准 GQA 额外加两个投影矩阵:一个索引 query(每个 GQA group 一个头)、一个跨 group 共享的索引 key。流程是:
- 对可见的 key token 打分;
- 把序列切成固定大小的块,每个块用 max-pooling 聚合成一个块分数;
- 对每个 GQA group 独立选出 top-k 个块。
用公式表示,先算索引分支的 token 级打分,再用 max-pooling 压到块级( 表示第 个块, 保证因果性):
然后对块分数取 top-k,得到这个 group 的选块集合:
关键点是:打分用的是索引分支专属的轻量 ,和主分支的 Q/K 完全独立——这正是它「轻」的来源。
两个关键细节决定了它好不好用:
- 块级而非 token 级选择 —— 这是对 GPU 友好的根本原因,把不规则的稀疏访问变成规则的块访问。
- 永远强制包含当前块(query 所在的局部块),无论它分数高低 —— 这是训练稳定性的关键保障。
主分支(Main Branch,精确)
拿到块索引集 后,主分支只在这些块的可见 token 上做标准的缩放点积 softmax 注意力:
其中 表示只取出选中块里的 key。同一 group 内所有 query 头共享这套选块结果、但各自保留自己的 query 投影。于是单 query 的注意力成本从 降到 ,即与序列长度脱钩、变成常数级。
训练:top-k 不可导怎么办
top-k 的输出是一个离散的选择(哪些块被选中 / 没选中),从连续的分数到这个离散结果的映射是「阶梯函数」,几乎处处梯度为 0、在临界点又不可导,所以没有有用的梯度能传回去。
top-k 选择不可导,语言模型的损失没法直接训练索引的 Q/K 投影。MSA 用一套「KL 散度损失对齐加三件套稳定器」解决:
- KL 对齐损失:让索引分支的分布去对齐主分支在选中 token 上的(组平均)分布,相当于主分支当老师,给索引器一个直接的学习信号。
- 梯度切断(Gradient Detach):索引分支的梯度与主分支切断,避免两者互相干扰。
- 索引器预热(Indexer Warmup):先单独热身索引器再放开。
- 强制局部块(Local Block):前面提到的强制保留最近块。
其中 KL 对齐是整套训练的核心。在选中 token 集合 上,分别定义索引分支分布(学生)和主分支分布(老师,对组内 个 query 头取平均):
训练目标就是让学生去逼近老师(老师一侧做梯度切断,不回传):
直觉很干净:主分支真正关注了谁,索引器就应该学会去选谁。
值得注意的是,MSA 既支持从头训练,也支持从预训练好的 GQA 权重近乎无损转换——这给了部署上很大的灵活度。
Kernel:把理论稀疏兑现成真实加速
这是这篇报告真正的含金量所在。稀疏注意力最大的坑就是「算力省了但墙钟没快」,MSA 在 kernel 上做了几件事:
- 免指数的 top-k:选块阶段绕开 softmax 的指数运算,专门为小 k 场景优化;
- 以 KV 为外层的组织方式:让选中的 KV 块去聚拢对应的 query、拼起来填满张量核的矩阵乘,应对块「热度」严重不均的问题;
- 预调度分块加两阶段合并:避免原子更新;
- 训练侧:把稀疏 KL 损失需要的 LSE 计算融进前向,反向用持久化的负载均衡。
实验数字
- 规模:109B 参数 MoE 模型,原生多模态,3T token 从头训练;
- 质量:下游文本与多模态评测 与 GQA 持平;
- 效率(100 万上下文):每 token 注意力计算 降 28.4 倍;H800 上 prefill 14.2 倍、decoding 7.6 倍墙钟加速;
- 公开释放:推理 kernel 已公开,M3 模型权重也以开放权重形式发布。
一个加分项:从头训练通过,比后期改造续训更可信——稀疏注意力的典型失败模式是「平均分好看,但某些长上下文召回场景悄悄崩了」,原生训练能让稀疏模式进入预训练梯度,降低这种风险。
M3 的评测表现
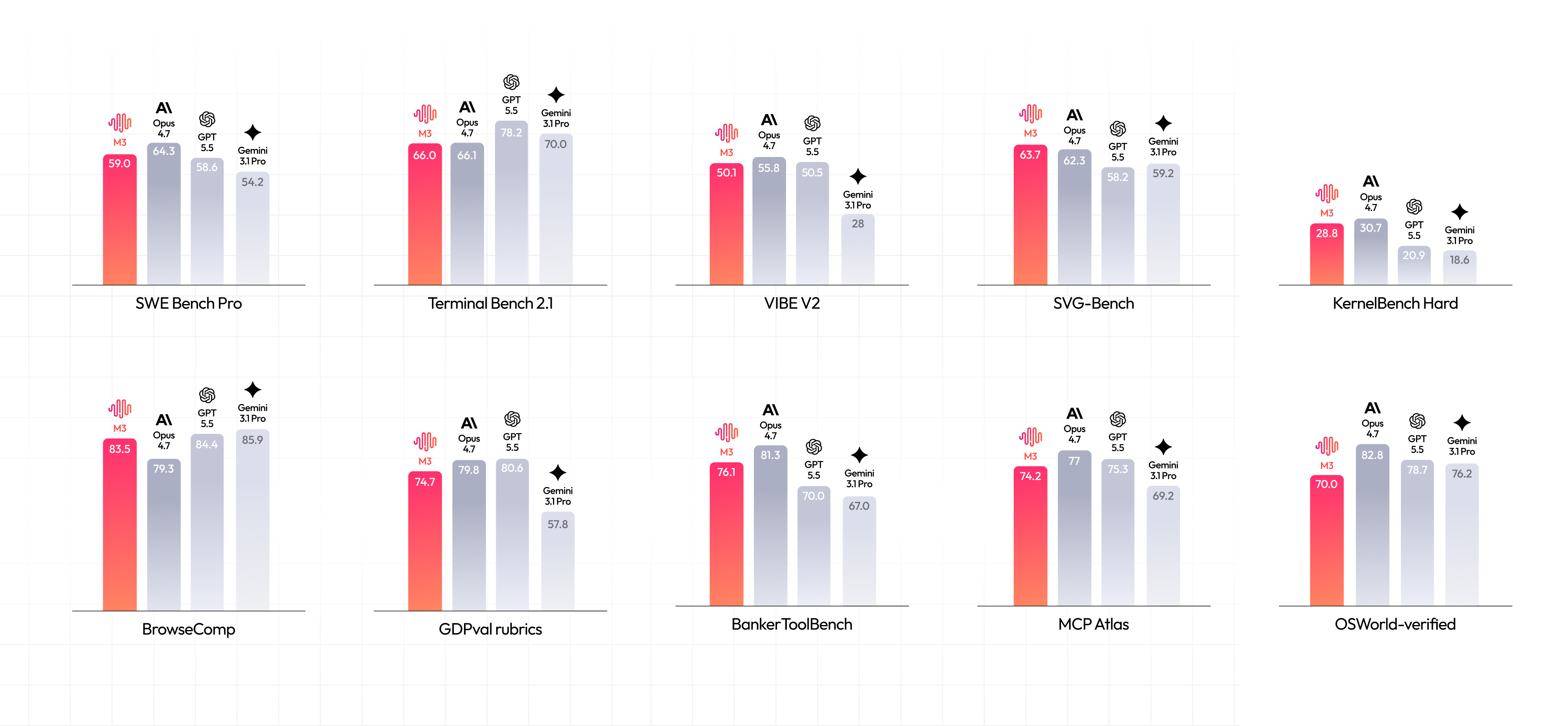
官方披露里,M3 的强项不是传统 MMLU 式静态知识题,而是 coding、agent、浏览检索、工具调用和长程任务:BrowseComp 为 83.5,SWE Bench Pro 为 59.0,Terminal Bench 2.1 为 66.0,OSWorld-verified 为 70.0,KernelBench Hard 为 28.8。
Artificial Analysis 6-16 关于 Artificial Analysis Intelligence Index 的帖子:
在开源权重模型中,DeepSeek V4 Pro(max,44)和 MiniMax M3(44)领先,其次是 Kimi K2.6(43)和 MiMo-V2.5-Pro(42)。

横向对比:四家稀疏注意力的取舍
| 维度 | MoBA(Moonshot 25.02) | NSA(DeepSeek 25.02) | DSA(DeepSeek-V3.2-Exp 25.09 / V3.2 25.12) | MSA(MiniMax M3 26.06) |
|---|---|---|---|---|
| 底座 | MHA / GQA | GQA | MLA(MQA 模式) | GQA |
| 选择粒度 | 块级 | 块级(选择分支) | token 级 | 块级 |
| 核心结构 | 混合专家式动态选块 | 三分支:压缩+选择+滑窗,门控融合 | 轻量索引器+token 级 top-k | 双分支:索引+主分支 |
| 索引器 | 路由打分 | 三路径各自打分后门控 | 闪电索引器:FP8、ReLU、共享 key | 块级 max-pooling,每组独立 |
| 训练 | 可训练,全注意力/稀疏可切换 | 原生从头可训练 | 续训改造+KL 预热 | 从头训练(也支持 GQA 转换)+KL+切断+预热 |
| 落地 | Kimi | 研究验证 | DeepSeek V3.2 | MiniMax M3 |
写在最后:一次高质量的增量
MSA 本质上是「现有技术的优雅工程化集大成」。机制层面,动态稀疏选择、局部保底、KL / 路由训练等部件已有先例;MSA 的具体组合是标准 GQA 上的 blockwise top-k 加 forced local block。它和 DSA 的差异不是谁先谁后的关系,而是同一目标下的不同工程取舍:DSA 走 token 级 top-k,并且建在 MLA 之上。真正更接近范式转移的东西在底座、不在稀疏这一层——MLA 改变了 KV 内存随长度增长的规律,稀疏注意力更多是底座上的增量。
所以 MSA 的价值不在「发明了什么」,而在别处:系统化的 kernel、大规模从头训练的可复现验证、公开释放,以及真正上线产品。
到 M3 这个时间点,要不要做稀疏注意力已经不是问题——Moonshot、DeepSeek、MiniMax 三家一线全压上来且都上了生产。现在拼的是「索引器多轻、kernel 多扎实、训练配方多省」。
欢迎关注微信公众号👏

欢迎微信扫码加入我的付费知识星球👏
