- Published on
LLM 文本生成解码策略指南(二):入选 NeurIPS 2022的对比搜索
- Authors

- Name
- Jason Huang
- @zesenhhh
Table of Contents
简介
A Contrastive Framework for Neural Text Generation 主要介绍了一种新的神经网络文本生成方法,即简单对比框架(SimCTG),它通过引入对比训练目标和对比搜索解码策略来解决文本生成中的退化问题。文本退化通常表现为生成的文本不自然且包含不必要的重复。传统的最大似然估计(MLE)训练方法和基于搜索的解码策略,如贪心搜索和束搜索,往往会导致这种问题。为了解决这个问题,研究提出了一个新的对比训练目标(LCL),用于校准模型的表示空间,使得不同词的表示更加分散和对比性强。此外,研究还提出了对比搜索解码方法,该方法在保持与给定前缀的语义连贯性的同时,鼓励生成的文本多样性。
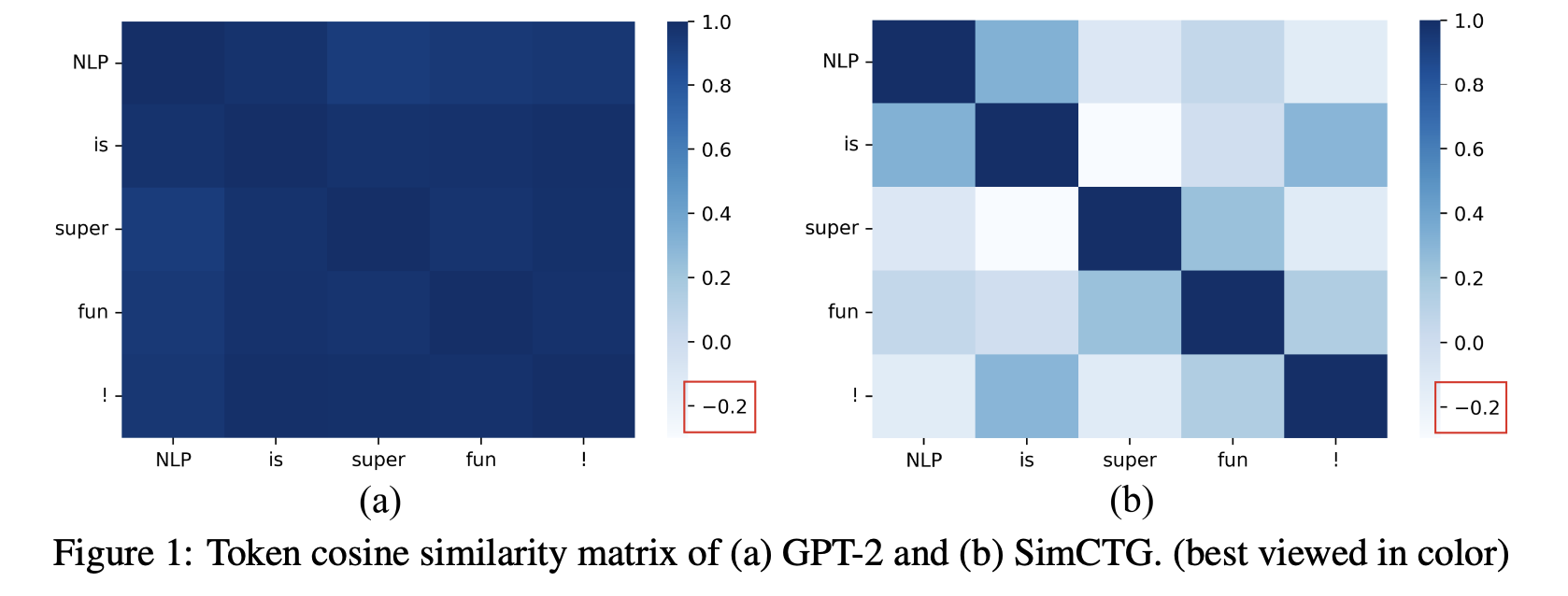
神经语言模型(如GPT-2)在生成文本时常面临表示分布的 anisotropic 问题,即模型生成的 token 表示在特征空间中过于集中,导致它们的余弦相似度过高(超过0.95),如图1(a)所示。这种高相似性使得不同 token 的表示难以区分,从而导致生成文本中出现重复性问题。相比之下,理想的 token 表示应呈现 isotropic 分布,令相似度矩阵更加稀疏,如图1(b)所示。这种分布能够确保不同 token 的表示更加区分化,进而避免生成退化(degeneration)问题。研究表明,isotropic 不仅能提升模型生成内容的多样性,还能有效提高生成文本的质量。
对比搜索的核心直觉在于:(i) 在每一步解码中,输出应该从模型预测的最可能候选集合中选择,以更好地保持生成文本与人工书写前缀之间的语义一致性(semantic coherence);(ii) 应保持生成文本的 token 相似度矩阵的稀疏性,以避免生成退化问题。
那么如何实现这个核心直觉?
Contrastive Objective
首先需要在模型训练阶段应用对比学习来校准语言模型的表示空间,在语言模型的训练中引入了对比目标 ,给定一个变长序列 :
其中,ρ∈ [-1, 1] 是预先确定的边际值,可以灵活控制对比学习的强度, 是模型生成的标记 的表示形式。相似度函数 s 计算标记表示之间的余弦相似度, 是同一个样本的相似度得分,为常数 1。
这个对比学习损失函数的设计可以类比为一个精心设计的座位优化问题。在特征空间中,我们需要为每个样本找到最优的"位置",这就像在一个专业会议中安排与会者的座位:同一研究领域的专家应当就座于便于交流的距离内,而不同领域的专家则自然会分布在不同的区域。
在数学表达上,当样本与自身的相似度显著高于它与其他样本的相似度(超过预设的边际阈值 ρ)时,损失函数返回 0,表示当前的特征表示已经达到了理想的状态。这种情况下,样本在特征空间中的"位置安排"是最优的。
反之,如果一个样本与其他无关样本的相似度异常接近,或甚至超过了其自相似度,损失函数会产生一个正向的惩罚项。这个惩罚机制驱动模型调整其参数,优化特征表示,使得样本在特征空间中的分布更加合理:增强样本与自身的相关性,同时与其他样本保持适当的特征距离。
这种设计确保了模型能够学习到合理的特征表示空间,在保持语义相似性的同时实现充分的特征区分度,这对于提升生成文本的质量和多样性具有重要意义。
通过使用 进行训练,模型学会了拉开不同标记之间的距离。因此,总体训练目标 定义为:
就是原本通过最大似然估计(MLE)训练模型的目标函数。当 ρ 为 0 的时候,Contrastive Objective 即退化为原始的目标函数。
Contrastive Search
使用上述目标函数训练模型后,在模型解码生成文本时,采用对比搜索策略进行解码。
在每个解码步骤中,对比搜索的主要思想是:(i) 生成的输出应从模型预测的最有可能的候选集中选择;(ii) 生成的输出相对于之前的上下文应具有足够的区分度。这样,生成的文本就能 (i) 更好地保持与前缀语义的一致性,同时 (ii) 避免模型退化。
其中, 是语言模型概率分布 中前 k 个预测的集合。第一项,即模型置信度,是语言模型预测的候选 v 的概率。第二项,即退化惩罚,衡量的是 v 相对于之前上下文 的区分度,而函数 s(⋅,⋅) 计算的是标记表示之间的余弦相似度。
更具体地说,退化惩罚被定义为 v 的标记表示(即 hv )与上下文 中所有标记表示之间的最大余弦相似度。在这里,候选表示 hv 是由语言模型根据 和 v 的连接计算得出的。直观地说, v 的退化惩罚越大,意味着它(在表示空间中)与上下文越相似,因此更有可能导致模型退化问题。超参数 α 可以调节这两个部分的重要性。当 α=0 时,对比搜索会退化为的贪婪搜索。
在 transformer 库中启用和控制对比搜索行为的两个主要参数是 penalty_alpha 和 top_k :
from transformers import AutoTokenizer, AutoModelForCausalLM
checkpoint = "openai-community/gpt2-large"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
prompt = "Hugging Face Company is"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, penalty_alpha=0.6, top_k=4, max_new_tokens=100)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
参考
- A Contrastive Framework for Neural Text Generation
- Contrastive Search Is What You Need For Neural Text Generation
- Generating Human-level Text with Contrastive Search in Transformers 🤗

