- Published on
先有 DeepSeek-V3 还是先有 R1?一文解读 V3 与 R1 是怎么相互炼成的
- Authors

- Name
- Jason Huang
- @zesenhhh
Table of Contents
不知道其他人读 DeepSeek 的论文的时候有没有这个问题,春节期间我刚开始读 DeepSeek-V3 与 R1 的论文的时候,我一直有个“先有鸡还是先有蛋”的问题:V3 借用了 R1 的能力提升了推理能力,R1 又借助了 V3 的能力提升了通用能力,那是先有 V3 还是先有 R1?
从发布时间上看,V3 发布早于 R1。
V3 的论文中提到:
During the post-training stage, we distill the reasoning capability from the DeepSeekR1 series of models...
在后训练阶段,我们从 DeepSeekR1 系列模型中提炼出推理能力...
For reasoning-related datasets, including those focused on mathematics, code competition problems, and logic puzzles, we generate the data by leveraging an internal DeepSeek-R1 model.
对于推理相关的数据集,包括数学、代码竞赛问题和逻辑谜题,我们利用 DeepSeek-R1 内部模型生成数据。
R1 的论文中提到:
For non-reasoning data, such as writing, factual QA, self-cognition, and translation, we adopt the DeepSeek-V3 pipeline and reuse portions of the SFT dataset of DeepSeek-V3.
对于非推理数据,如写作、事实问答、自我认知和翻译,我们采用 DeepSeek-V3 管道,并重复使用 DeepSeek-V3 的 SFT 数据集的部分内容。
For general data, we resort to reward models to capture human preferences in complex and nuanced scenarios. We build upon the DeepSeek-V3 pipeline and adopt a similar distribution of preference pairs and training prompts.
对于一般数据,我们采用奖励模型来捕捉复杂和细微场景中的人类偏好。我们以 DeepSeek-V3 管道为基础,采用类似的偏好对分布和训练提示。
【黑人问号脸. jepg】
左脚踩右脚螺旋上升?
预训练与后训练
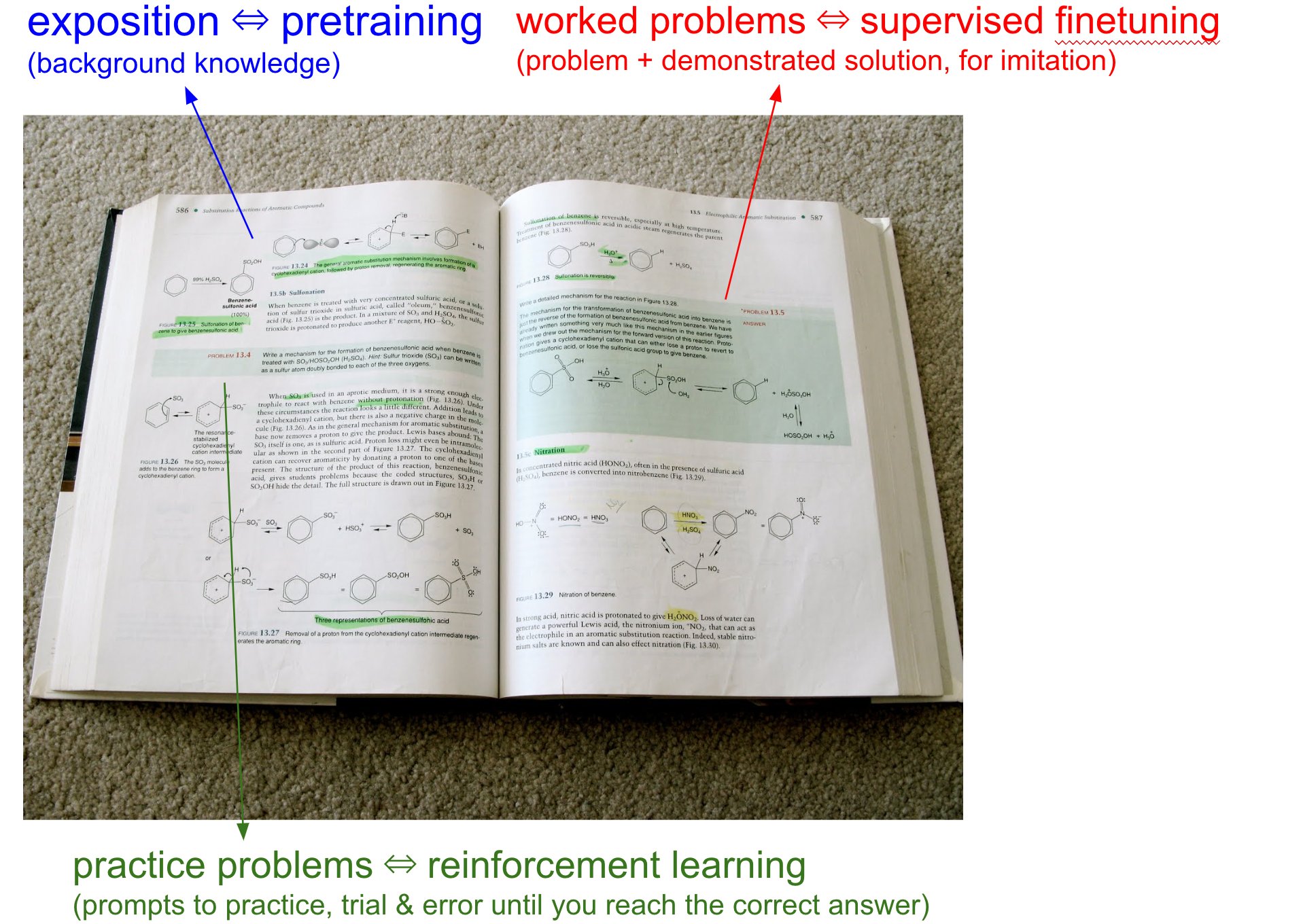
这里先引用 Andrej Karpathy 的 X 帖子说明一下预训练(pre-training)和后训练(post-training)这两个模型训练阶段,以及 SFT(Supervised Fine-Tuning,有监督微调)和 RL(Renotercement Learning,强化学习)这两个方法在后训练中的作用。
NOTE
预训练是模型训练的第一阶段,通常在大量的无标签数据上进行。这一阶段的目标是让模型学习到广泛的知识和语言结构,类似于为模型打下基础。例如,语言模型通过分析大量文本数据学习到语法、词汇、句子结构等。
预训练的过程帮助模型掌握一般性的规律和信息,使其具备较强的泛化能力。预训练的过程通常不需要人工标注数据,而是通过自动化学习从海量数据中提取特征。
Andrej Karpathy 将预训练比作学生阅读教科书中的“背景信息/说明(exposition)”,即通过大量文本(比如互联网数据)让模型积累广泛的背景知识。
SFT 和 RL 一般包含在后训练的阶段中。
NOTE
后训练是在预训练之后进行的,它是对模型进行专门化的训练,使得模型能够在特定任务或领域上表现得更好。后训练通常需要使用有标签的数据,并且关注于某个特定的应用场景。
后训练的目的是让预训练模型更好地适应具体任务的需求。通过这种方式,模型能够在特定领域中表现得更优秀,并更好地处理特定任务。
Andrej Karpathy 将 SFT 比作教科书中的“已解决的问题(worked problems with solutions)”,即专家(人类)提供的具体问题和理想解决方案(带解题过程的例题),模型通过模仿这些示范来学习。
SFT 是后训练的关键步骤。预训练后的模型被进一步训练在标记数据集上(问题-答案对),让它学会生成特定任务(如对话助手)的理想响应。SFT 帮助模型“模仿专家”,提升在特定场景下的精准性和适用性。
Andrej Karpathy 将 RL 比作教科书中的“练习问题(practice problems)”,即没有明确解决方案的问题(只带标准答案,不带解题过程的练习题),模型需要通过试错(trial & error)来找到正确答案。
RL 可显著增强模型的推理能力。我们已经让 LLM 进行了大量的预训练和 SFT,但 RL 是一个新兴领域,具体来说是 RL 的 scale up 规模化是个新型领域。
DeepSeek-V3-Base
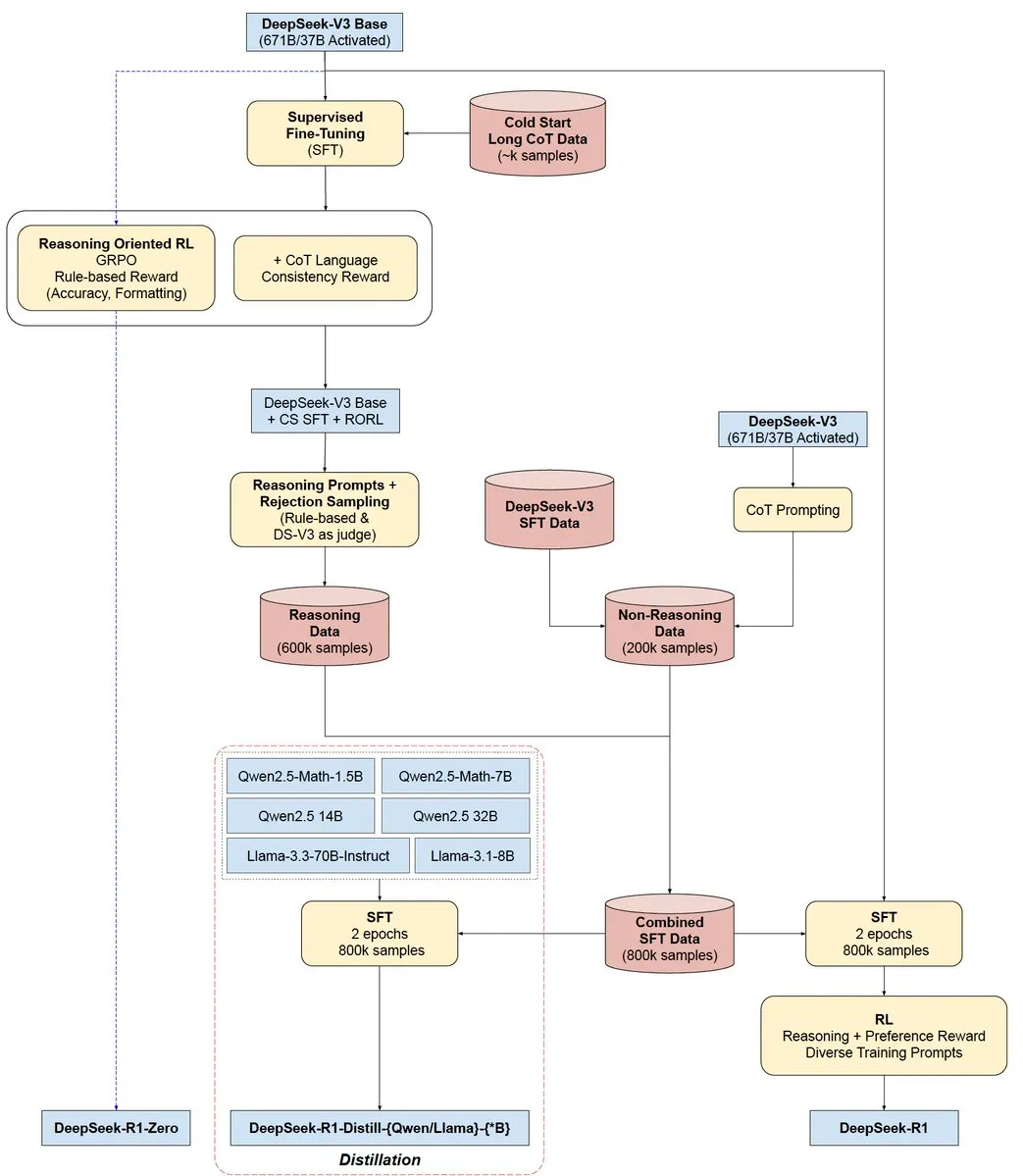
初次读论文的时候我忽略了 DeepSeek-V3-Base,把 DeepSeek-V3-Base 误以为就是 V3,但其实不是,DeepSeek-V3-Base 其实是正式版本的 V3 与 R1 的基座,V3 与 R1 都是在 DeepSeek-V3-Base 的基础上后训练得到的。
也就是说最开始是先有 DeepSeek-V3-Base,才有 V3 与 R1。
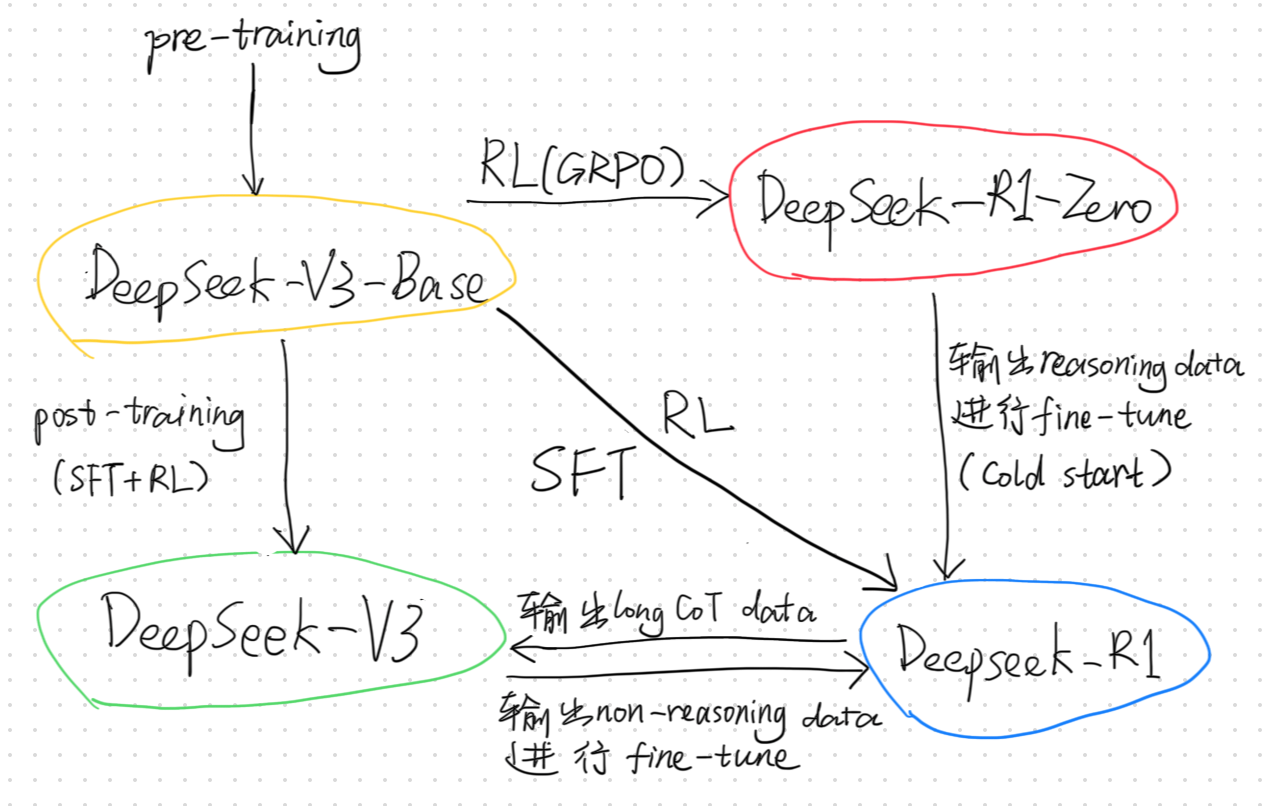
我画了一幅简单的示意图,如上图所示,DeepSeek-V3-Base 是在 14.8 万亿个高质量和多样性 token 的数据上预训练而来,这是 V3 与 R1 的起点。
DeepSeek-V3
正式版的 V3 是在 DeepSeek-V3-Base 的基础上进一步后训练,通过 SFT 和 RL 的方法训练得到的。在 V3 的后训练的过程中,采用了基于 R1 微调的专家模型输出的推理数据提升了推理能力;而非推理数据则采用了 DeepSeek-V2.5 生成对应的数据,加上人类标记的数据进行微调。
利用 R1 进行微调专家模型的过程可以简洁地分为以下三个步骤:
- 生成 SFT 样本
使用 R1 模型生成响应,并将其与问题和精心设计的系统提示结合,形成监督微调(SFT)样本。样本分为两种格式:<问题, 原始回答><系统提示词, 问题, R1回答>
系统提示包含指导模型生成带有反思和验证机制的响应的指令。
- RL 训练
在 RL 阶段,模型通过高温采样生成响应,学习整合 R1 生成数据和原始数据的模式。经过数百个 RL 步骤后,专家模型能够自然融入 R1 模式,提升整体性能。 - 拒绝采样
RL 训练完成后,实施拒绝采样,从专家模型生成的高质量数据中挑选最佳响应,作为最终 V3 的 SFT 数据。这种方法确保数据保留 R1 的高准确性,同时生成简洁有效的响应。
这时候 V3 的后训练用到了 R1,那 R1 又是从哪来的?
我不确定在 V3 的后训练过程中使用的是什么版本的 R1,猜测可能是经过冷启动和一轮 RL 训练后但还没有经过通用知识数据 SFT 的 R1。
DeepSeek-R1
有了预训练后的 DeepSeek-V3-Base,那 V3 和 R1 (包括 R1-Zero)可以同时在其基础上进行后训练,然后根据各自后训练的版本生成对应能力的数据,比如推理数据和通用数据,互相提供给对方进行后训练加强,最终得到如今大家在用 V3 和 R1(理解有误的话请随时评论区指正我)。
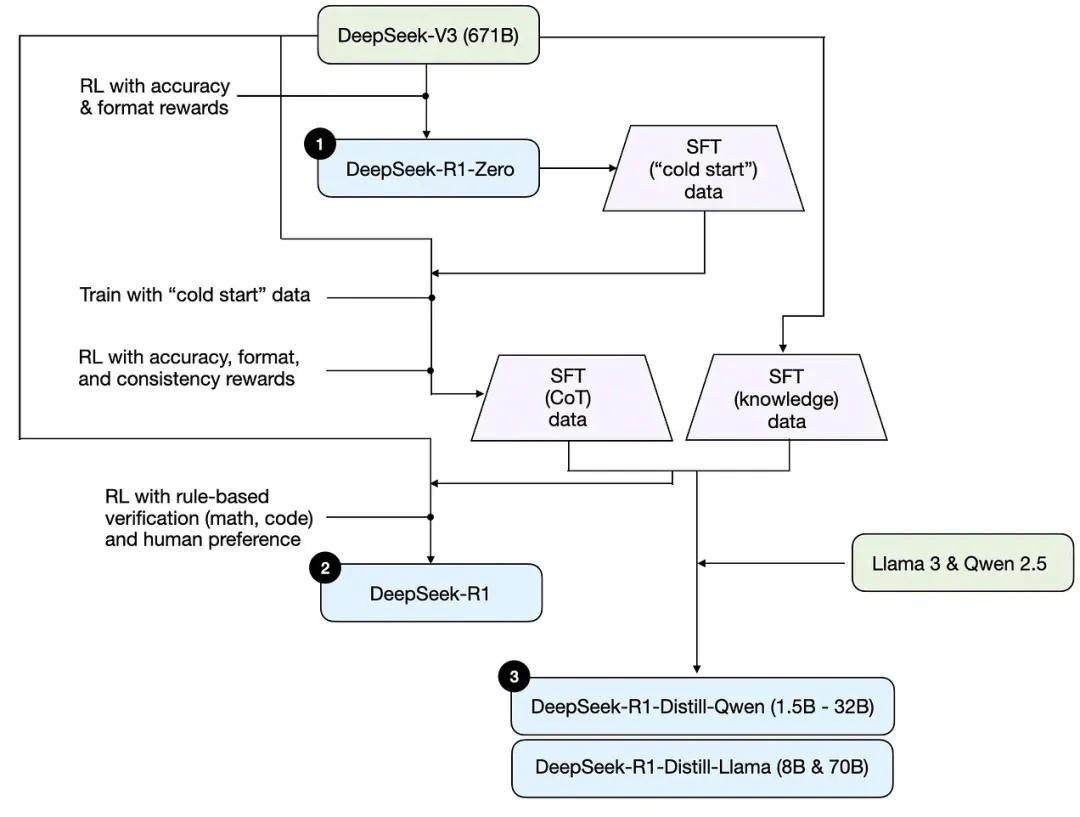
如上图所示,R1-Zero 是在 R1 之前通过纯粹的 RL 训练出来的,具有很强的推理能力,但是受限于语言混乱可读性差,为了训练一个用户友好的模型,使其不仅能生成清晰连贯的思维链 (CoT),还能展现强大的通用能力,因此才训练了 R1。
首先,我们已经有了 R1-Zero,因此可以用 R1-Zero 生成一些推理数据,在 DeepSeek-V3-Base 的基础上进行冷启动,作为 R1 的起点。
在进行冷启动数据微调后,采用了类似于 DeepSeek-R1-Zero 的大规模强化学习训练过程,重点提升模型在推理密集型任务(如编程、数学、科学和逻辑推理)上的能力。期间引入了语言一致性奖励由于缓解语言混杂的问题,最后将推理任务的准确性和语言一致性奖励结合起来,形成最终奖励,并在微调后的模型上继续进行强化学习训练,直到模型在推理任务上收敛。
然后利用 V3 生成通用的数据集结合收集的推理数据集进行拒绝采样和监督微调(Rejection Sampling and Supervised Fine-Tuning),此时的 V3 可能是只经过非推理数据微调的版本。
最后为了对齐人类的偏好与价值观,去除有害性和增强有用性,DeepSeek 在以上的基础进行了最后的一轮全场景的 RL 训练。
至此,R1 全部训练完成,成为开源社区中大家下载部署的那个版本。
总结上述流程如下图:
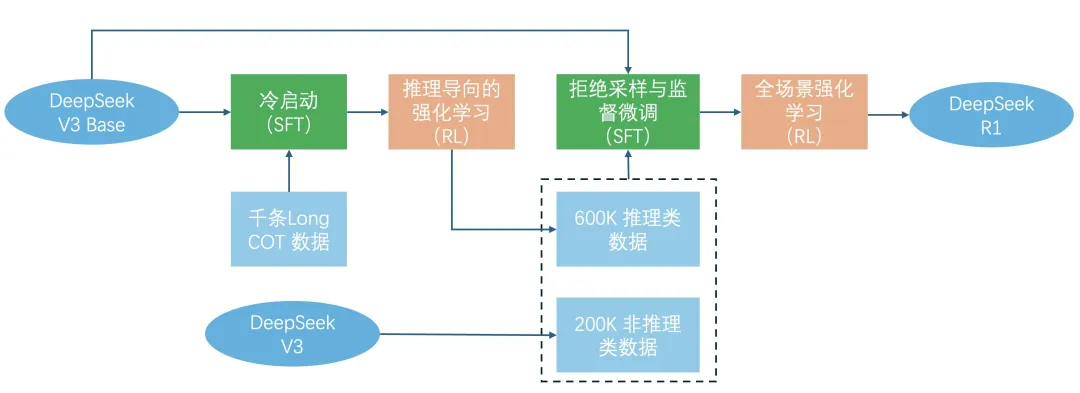
带有更多细节的流程图解可参考下图:
参考
- DeepSeek-V3 Technical Report
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Renotercement Learning
- Andrej Karpathy 的 X 帖子
- 最后一张流程图@SirrahChan
- Understanding Reasoning LLMs
- 万字长文详解DeepSeek核心技术
- 万字赏析 DeepSeek 创造之美:DeepSeek R1 是怎样炼成的?

