- Published on
为什么GPT需要Prompt?从GPT1到GPT3的演变解读
- Authors

- Name
- Jason Huang
- @zesenhhh
Table of Contents
伴随着 ChatGPT 的横空出世,各种各样像是“咒语”一样的 prompt engineering 技巧层出不穷,在 GPT 之前的机器学习模型都是直接输入样本数据,得到输出,并没怎么加入 prompt 一起作为输入,但为什么 GPT 需要 prompt?
GPT 作为一种强大的语言模型,拥有海量的知识储备和强大的语言生成能力,但它本质上是一个工具,需要明确的指示才能发挥作用。
实践中对于用户来说,prompt 对于 GPT 而言至关重要,主要有以下几点:
- 明确任务目标: prompt 可以清晰地告诉 GPT 用户想要它做什么,例如翻译、写作、问答等等。
- 提供上下文信息: prompt 可以提供背景信息,帮助 GPT 理解用户意图,并生成更符合语境的输出。
- 引导生成方向: prompt 可以通过关键词、语句结构等方式,引导 GPT 生成符合特定风格、主题或格式的文本。
- 控制输出内容: prompt 可以设定输出内容的长度、格式、语气等,确保 GPT 生成的文本符合用户的需求。
那对于研究者和 AI 工程师来说,为什么 GPT 需要 prompt 呢?本质上 prompt 的作用是什么?prompt 给 GPT 带来的是什么?
GPT 的目标函数
GPT 的目标函数之一是 最大化语言模型的似然函数。换句话说,它旨在学习一个模型,该模型能够预测给定序列中下一个词出现的概率(next token prediction)。
其目标函数可以表示如下:
其中, 是上下文窗口的大小,而条件概率 则是通过一个带有参数 的神经网络来建模的。这些参数采用随机梯度下降法进行训练而得到。
NOTE
想象一下,你正在学习一门新的语言,你想要理解一个句子中下一个词是什么。你可能会根据之前出现的词语来猜测下一个词,例如,如果句子开头是 "The cat sat on the...",你可能会猜测下一个词是 "mat"。
最大化语言模型的似然函数就是让模型学习这种猜测能力。它让模型学习一个概率分布,这个概率分布描述了在给定之前词语的情况下,下一个词出现的可能性。
例如,模型可能会学习到,在 "The cat sat on the" 之后,"mat" 的概率很高,而 "apple" 的概率很低。
最大化似然函数的目标是让模型学习一个概率分布,这个概率分布能够尽可能准确地预测下一个词出现的可能性。换句话说,它希望模型能够像一个精通语言的人一样,根据上下文来猜测下一个词。
通过最大化似然函数,模型可以在 pre-training 阶段学习到语言的统计规律,从而能够生成更流畅、更自然的文本。
TIP
最大化似然函数这个目标函数的含义:
- 模型的目标是学习一个能够预测下一个词出现的概率分布。
- 最终生成的文本序列,是所有组成这段文本的词语在该模型下的最大联合概率所对应的序列,也就是模型认为最有可能出现的词语序列。
- 通过最大化似然函数,模型可以学习到语言的统计规律,从而能够生成更流畅、更自然的文本。
GPT 的目标函数与其他语言模型的目标函数类似,但它有一些独特的特点:
- 自回归模型: GPT 是一个自回归模型,这意味着它使用前一个词来预测下一个词。
- 单向模型: GPT 是一个单向模型,这意味着它只能使用过去的信息来预测下一个词,而不能使用未来的信息。
IMPORTANT
由于 GPT 使用的是预测下一个词的目标函数,因此在实际应用中,通常会先提供一段句子或几个词作为输入起点,接着 GPT 会根据这些输入生成后续最有可能出现的词语。因此,GPT 生成的文本内容在很大程度上依赖于提供的上下文。换句话说,这些上下文实际上就是 prompt 的雏形,它们引导了生成结果的方向。
众所周知,GPT 的底层架构是 Transformer,但是由于 GPT 选择的目标函数范式是使用前一个词来预测下一个词,类似于“预测未来”,所以 GPT 一般只使用 Transformer 的 Decoder,因为 Decoder 会有掩码机制在训练阶段来屏蔽掉未来的信息,而 Encoder 则会看到所有序列的信息。
作为对比,比 GPT-1 晚发表的 BERT(Bidirectional Encoder Representations from Transformers)使用的是 Transformer 的 Encoder 部分。BERT 的目标函数范式是双向的,即它在训练时会同时考虑句子中前后文的信息,因此能够看到句子中所有位置的词。为了实现这一点,BERT 在训练过程中引入了掩码语言模型(Masked Language Model, MLM),即随机屏蔽句子中的一些词,然后让模型去预测被掩盖的词,类似于“完形填空”。这种双向的上下文信息使得 BERT 在处理需要深入理解上下文的任务(如阅读理解、问答系统)上有很大的优势。
相比之下,GPT 只基于单向上下文,也就是通过给定的前文来预测下一个词,这使得它更适合生成性任务,如文本生成、对话生成等。而 BERT 的双向结构让它在理解性任务(如文本分类、实体识别等)上表现优异。两者的设计目标和应用场景不同,GPT 强调生成,BERT 强调理解。
“预测未来”难于“完形填空”,所以 GPT-1 在一开始并没有 BERT 流行,在 NLP 的任务上表现也差于 BERT。
无监督的多任务学习者
Language Models are Unsupervised Multitask Learners.
根据上下文来猜测下一个词的范式在一些传统的 NLP 任务上表现一般,因为采用这个目标函数本身就是难走的技术路线,且需要大量的数据,但是当 Ilya Sutskever 等人意识到 scaling law 的时候,那 next token prediction 的天花板就开始超乎人们的想象了。
next token prediction 的范式是比较难,但有 3 点好处:
- scaling law 下的暴力美学:随着模型规模、数据量和算力的增加,语言模型的性能持续提升。Ilya Sutskever 等人提出的 scaling law 揭示了这种扩展对多任务表现的显著影响。尽管基于预测下一个词的方法看似简单,大规模模型却能捕捉复杂的语言模式。这种"规模效应"展现了潜力,暗示着随着资源投入的增加,模型性能可能会持续突破。
- 统一各种 NLP 任务:next token prediction 的范式提供了一种通用的语言建模框架,能够处理几乎所有的 NLP 任务。这些任务(如文本生成、翻译、问答、摘要、对话等)可以被统一视为生成下一个词的过程,而不需要为每个任务设计特定的架构或目标函数。这种方法让 GPT 系列模型可以从一个简单的预测任务中,通过调整输入提示(prompt),在不同的上下文中灵活地应用于各种任务,从而实现模型的广泛通用性。
- 无监督学习的优势:next token prediction 是一种无监督学习方法,只需大量未标注文本数据即可训练。相比需要大量标注数据的监督学习,此方法更灵活、普遍适用。实际应用中,大规模标注数据昂贵难获,而未标注文本数据随处可得。GPT 模型因此可利用互联网庞大数据集自我训练,学习复杂语言模式和结构,无需手动标注数据集,极大扩展了其学习能力和应用场景。
以 GPT-2 论文中提到的翻译例子加以说明,该例子首次提到了 prompt:
We test whether GPT-2 has begun to learn how to translate from one language to another. In order to help it infer that this is the desired task, we condition the language model on a context of example pairs of the format
english sentence = french sentenceand then after a final ==prompt== ofenglish sentence =we sample from the model with greedy decoding and use the first generated sentence as the translation.
为了测试 GPT-2 是否具备翻译能力,论文中通过构造 prompt 的方式引导模型输出对应的翻译句子,GPT-2 的翻译任务提示是通过构建一个上下文环境,包含若干 英文句子 = 法文句子 的示例,来帮助模型理解任务的性质。然后,给定一个新的英文句子作为提示,模型基于之前的示例,利用语言生成能力生成法文翻译。这种方法不需要专门的翻译模型或额外训练,而是依赖于 GPT-2 在大规模语言数据上的预训练,利用它在不同语言上的理解能力来进行翻译。
事实上,GPT-2 掌握了大量语言知识,为了让 GPT-2 进行翻译,仅需通过一些例子加以引导。当 GPT-2 在足够大且多样化的数据集上进行训练时,它在许多领域和任务上都表现出色。在测试的 8 个 NLP 数据集中,GPT-2 在 7 个数据集上以 zero-shot 模式(==无需任何特定任务的微调或额外训练,无需计算梯度调整任何参数权重与模型架构==)达到了最佳水平。模型能够在 zero-shot 设置下执行多种任务,这表明通过在大规模多样化文本语料库上进行训练,模型已经能够在没有明确监督的情况下学会执行不同的任务。
NOTE
Zero-Shot Learning 也就是零样本学习,在 zero-shot 学习中,模型在没有见过特定任务的任何训练样本的情况下,直接执行该任务。也就是说,模型在完全没有进行任务相关微调或训练的情况下,利用其已有的知识推断出任务的解决方法。
Few-Shot Learners
Language Models are Few-Shot Learners.
NOTE
Few-Shot Learning 是少样本学习,指的是模型在仅提供少量(通常是几例)训练样本的情况下,学习并执行特定任务。但是在 GPT 中,这里的 few-shot 并不需要重新训练或微调模型,而是在输入模型的文本中除了目标句子外,额外添加几个例子,告诉模型要完成的任务类型以及要求,也可以说是 few-shot prompting。
GPT-2 证明了模型可以在 zero-shot 的模式下完成不同的 NLP 任务而无需微调和改变模型结构,它是个真正的无监督多任务模型,而在 GPT-3 的技术报告中重新定义了一个新概念,称之为 in-context learning,上下文学习。
For each task, we evaluate GPT-3 under 3 conditions: (a) “few-shot learning”, or ==in-context learning where we allow as many demonstrations as will fit into the model’s context window== (typically 10 to 100), (b) “one-shot learning”, where we allow only one demonstration, and (c) “zero-shot” learning, where no demonstrations are allowed and only an instruction in natural language is given to the model.
类比人类的学习,完全不给例子与给几个例子进行学习的区别还是很大的,下图也很好的印证了 Zero-Shot,One-Shot 和 Few-Shot 在不同模型参数下的表现,很明显,随着模型参数的增大(Scaling Law),Few-Shot 会越来越优于 Zero-Shot 和 One-Shot。
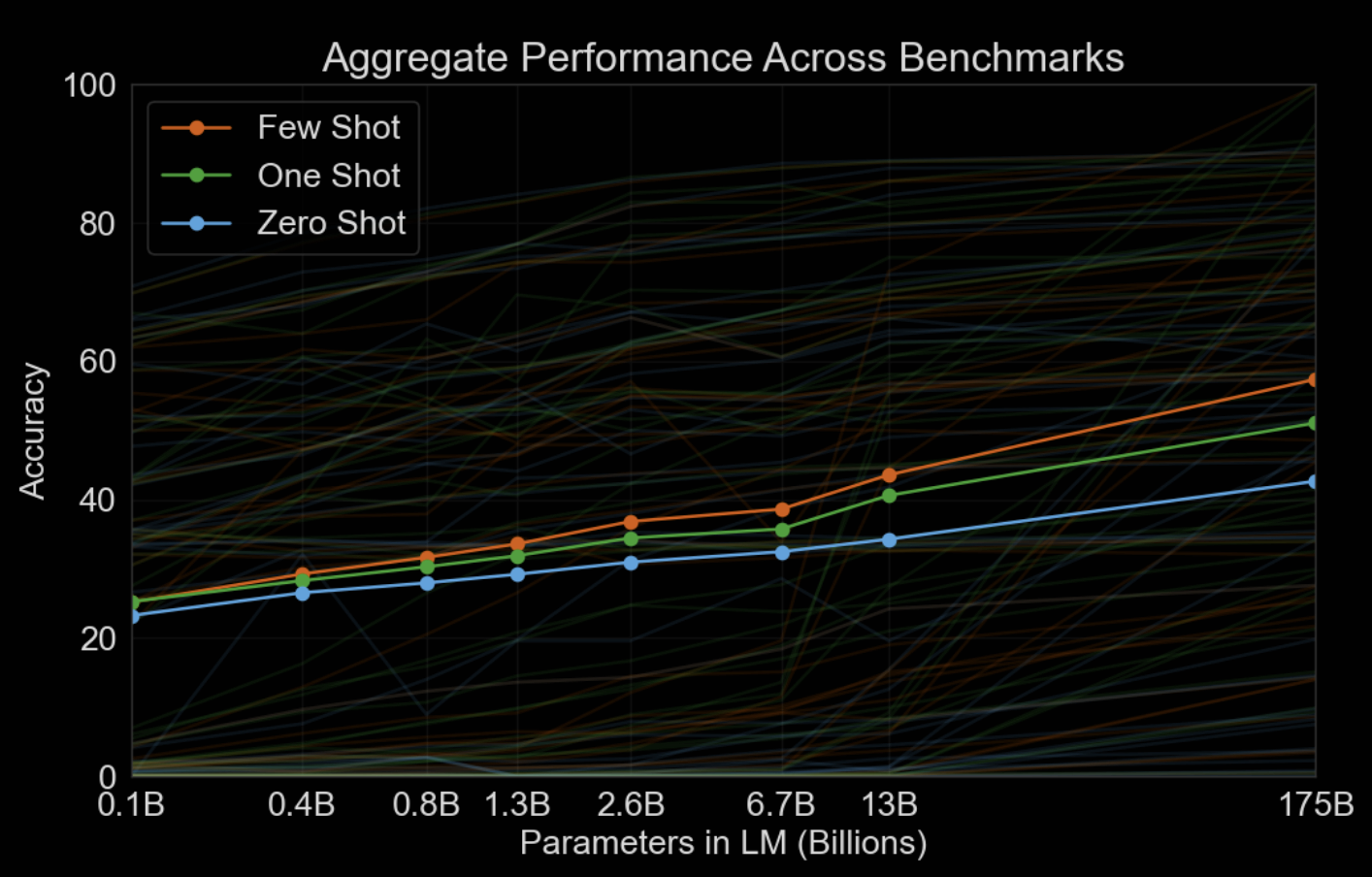
关于 Zero-Shot,One-Shot 和 Few-Shot 与传统的微调 fine-tuning 的区别见下图:
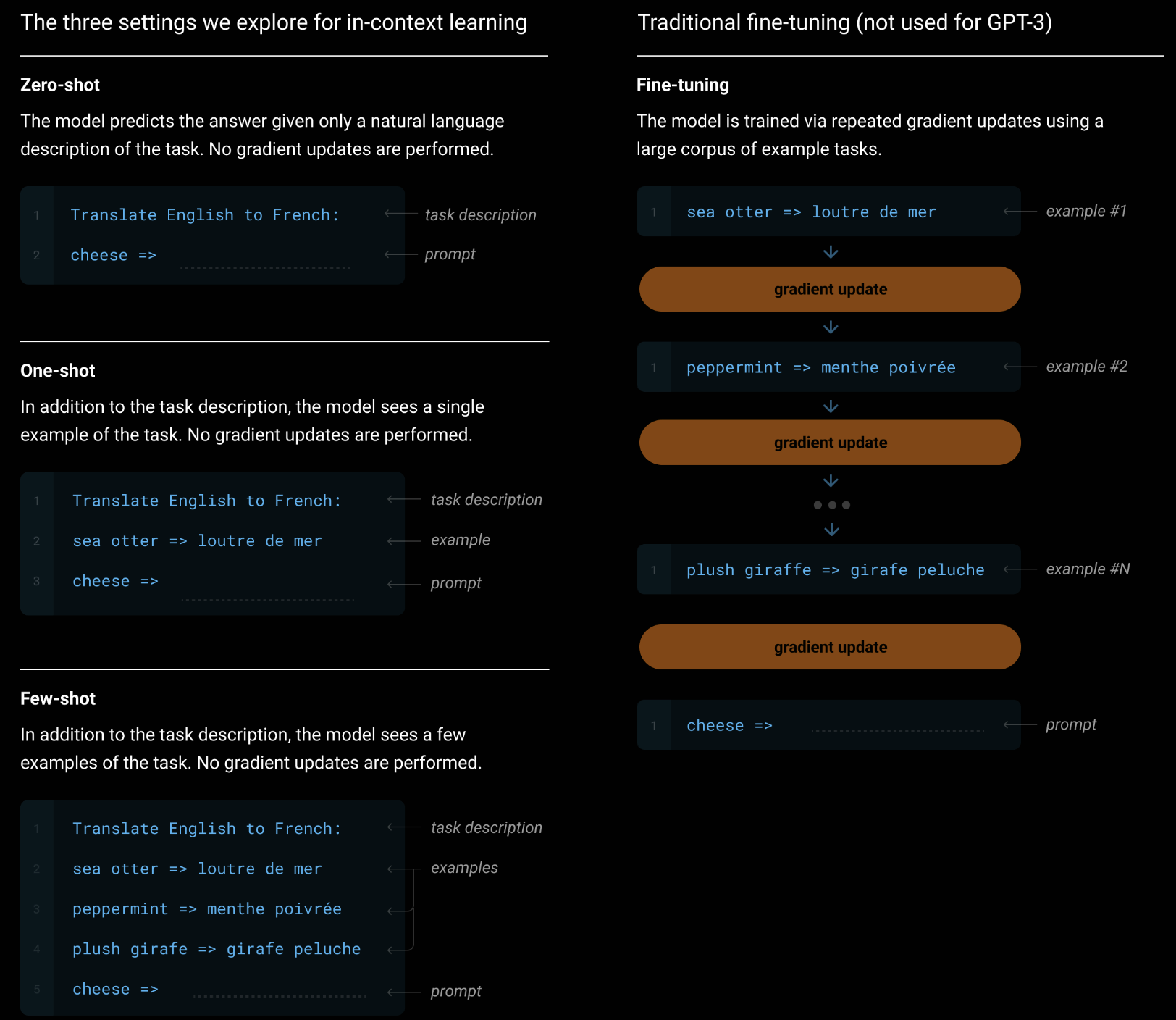
看到这里,估计就会完全明白现在的 prompt 与 prompt engineering 由何而来了,以及为什么现在大家都拼命卷上下文窗口。
简而言之,GPT 的目标函数是通过最大化下一个词的预测概率来训练的。在这种架构下,模型需要依赖前文信息来生成后续内容,因此 prompt 就成了向模型提供明确任务指示的关键手段。通过构造 prompt,我们能够帮助 GPT 更好地理解任务并根据 prompt 生成期望的文本。
GPT 通过海量的无监督数据进行训练,无论是翻译、摘要还是对话生成,所有任务都可以通过设计合理的 prompt 来适应 GPT 的生成方式,使其在不微调的情况下依旧表现出色。
Few-shot learning 的概念进一步揭示了 prompt 的重要性。在 GPT-3 中,通过在上下文中提供少量示例,模型能够更好地理解任务并给出符合预期的输出。这种无需重新训练或微调的上下文学习,展示了 prompt 在引导模型生成期望内容中的核心作用,也成为后来的 prompt engineering 的有效方法。
而上下文窗口的长度直接影响了 GPT 对 prompt 的理解能力。
- 短窗口: 当上下文窗口较短时,GPT 只能获取有限的文本信息,无法全面理解整个语境,生成的结果可能会偏离预期。
- 长窗口: 随着窗口长度的增加,GPT 能够获取更多的上下文信息,更好地理解用户意图,生成的结果也更符合要求。
Prompt 建议
根据上文,当明白 prompt 的由来以及 prompt 在 GPT 等大语言模型中的作用后,日常的对 ChatGPT 等模型对话的时候,或者开发者在调用其 API 构建产品的时候,除了清晰表达任务需求外,我强烈建议在 prompt 中加一两个该任务的例子,这在我使用 Llama 或者 Qwen 的过程中感受明显,比如写一个判断文本情感的 prompt 可以简单这样写:
Message: Hi Dad, you're 20 minutes late to my piano recital!
Sentiment: Negative
Message: Can't wait to order pizza for dinner tonight
Sentiment: Positive
Message: Hi Amit, thanks for the thoughtful birthday card!
Sentiment: ?
参考
- Improving Language Understanding by Generative Pre-Training(GPT-1)
- Language Models are Unsupervised Multitask Learners(GPT-2)
- Language Models are Few-Shot Learners (GPT-3)
- 李沐:GPT,GPT-2,GPT-3 论文精读【论文精读】
- Prompt Engineering with Llama 2&3

