- Published on
语义搜索与检索增强生成(RAG)
- Authors

- Name
- Jason Huang
- @zesenhhh
Semantic Search
IMPORTANT
Search by meaning
关键词搜索是多年来常见的搜索方法。但对于内容丰富的网站,如新闻媒体网站或在线购物平台来说,关键词搜索功能可能有限。通过将大型语言模型(LLM)整合到搜索中,可以显著提升用户体验,使他们能够更轻松地提问和查找信息。
课程概要:
- 基本的关键词搜索,这是许多搜索系统在语言模型可访问之前的基础。
- 通过使用重新排序方法,提高关键词搜索的结果质量,将最佳响应按照与查询相关性进行排名。
- 通过使用嵌入(embeddings)这种强大的自然语言处理工具来实现密集检索,利用文本的实际语义意义进行搜索,并显著改善结果。
- 通过处理大量数据进行实践,克服各种搜索结果和准确性的挑战。
- 将基于语言模型的搜索集成到您的网站或项目中。
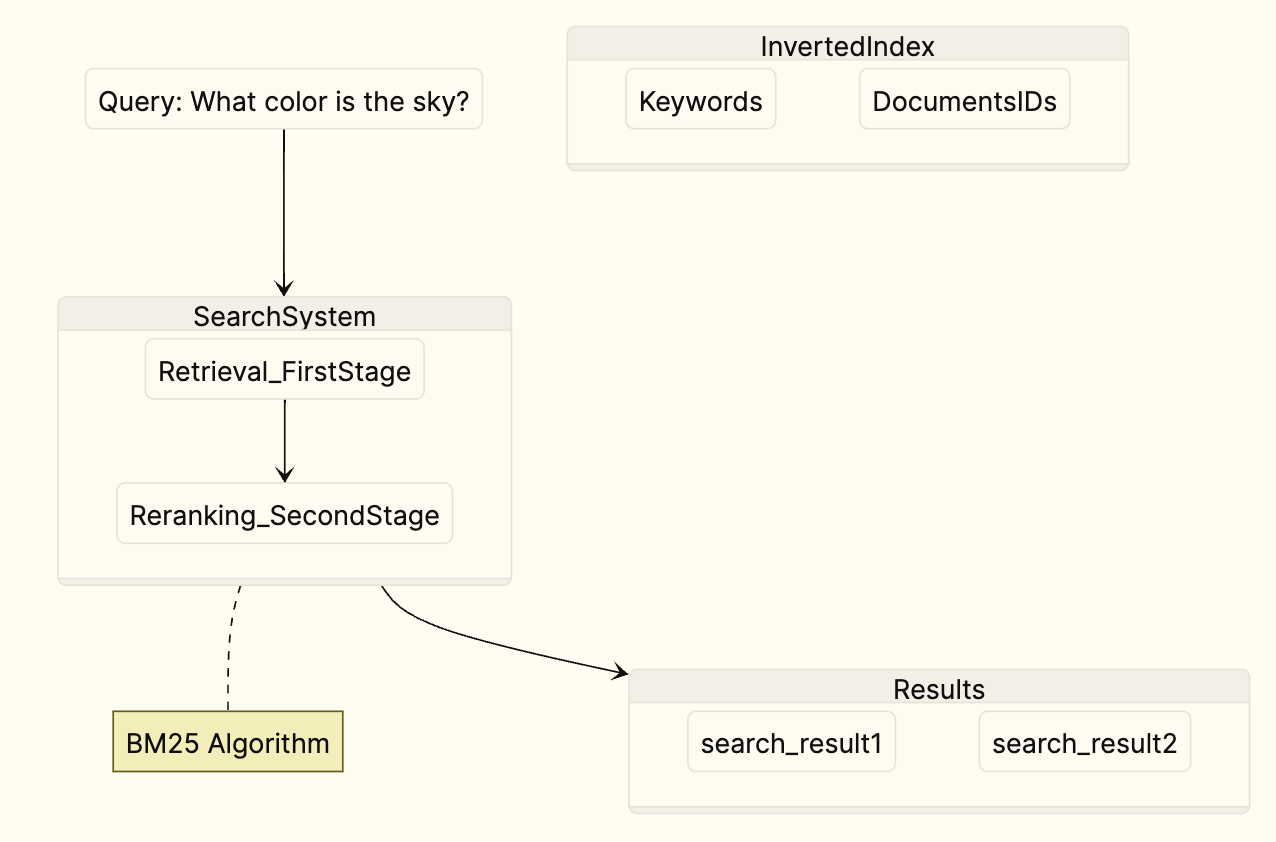
Keyword Search
Dense Retrieval
Hybrid Search: Keyword + Vector
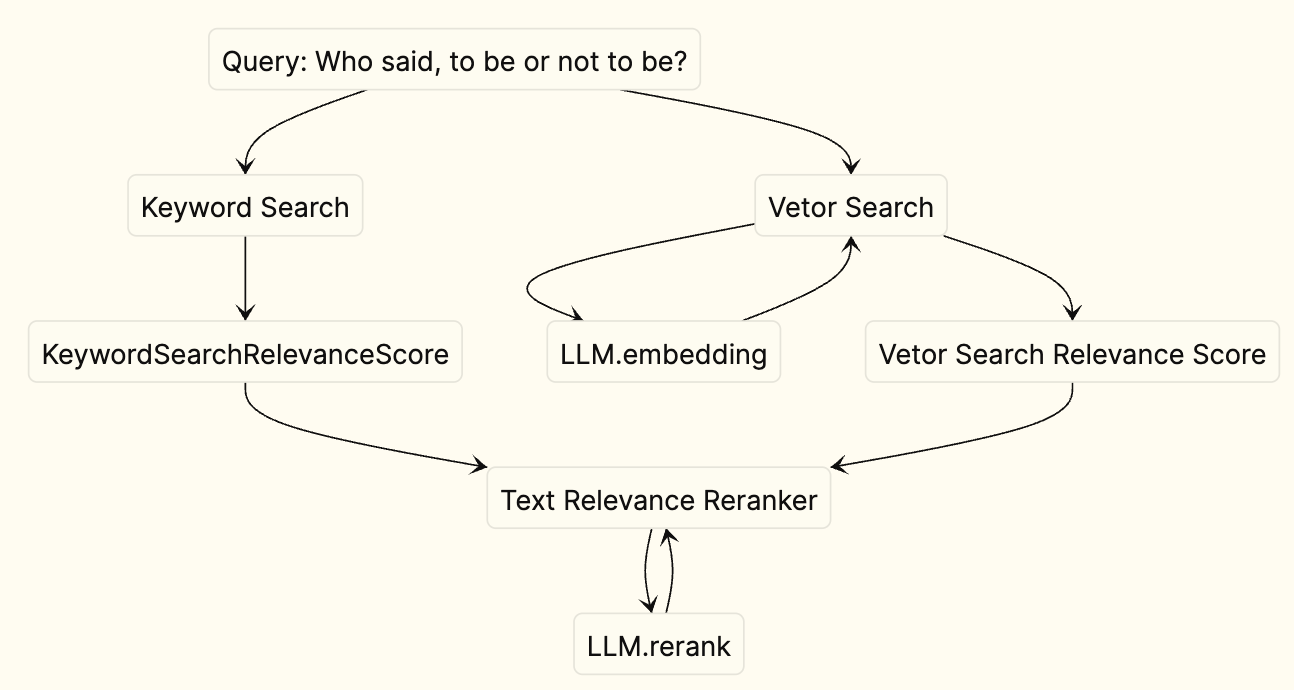
ReRank
Evaluating Search Systems
- Mean Average Precision (MAP)
- Mean Reciprocal Rank (MRR)
- Normalized Discounted Cumulative Gain (NDCG)
Generating Answers
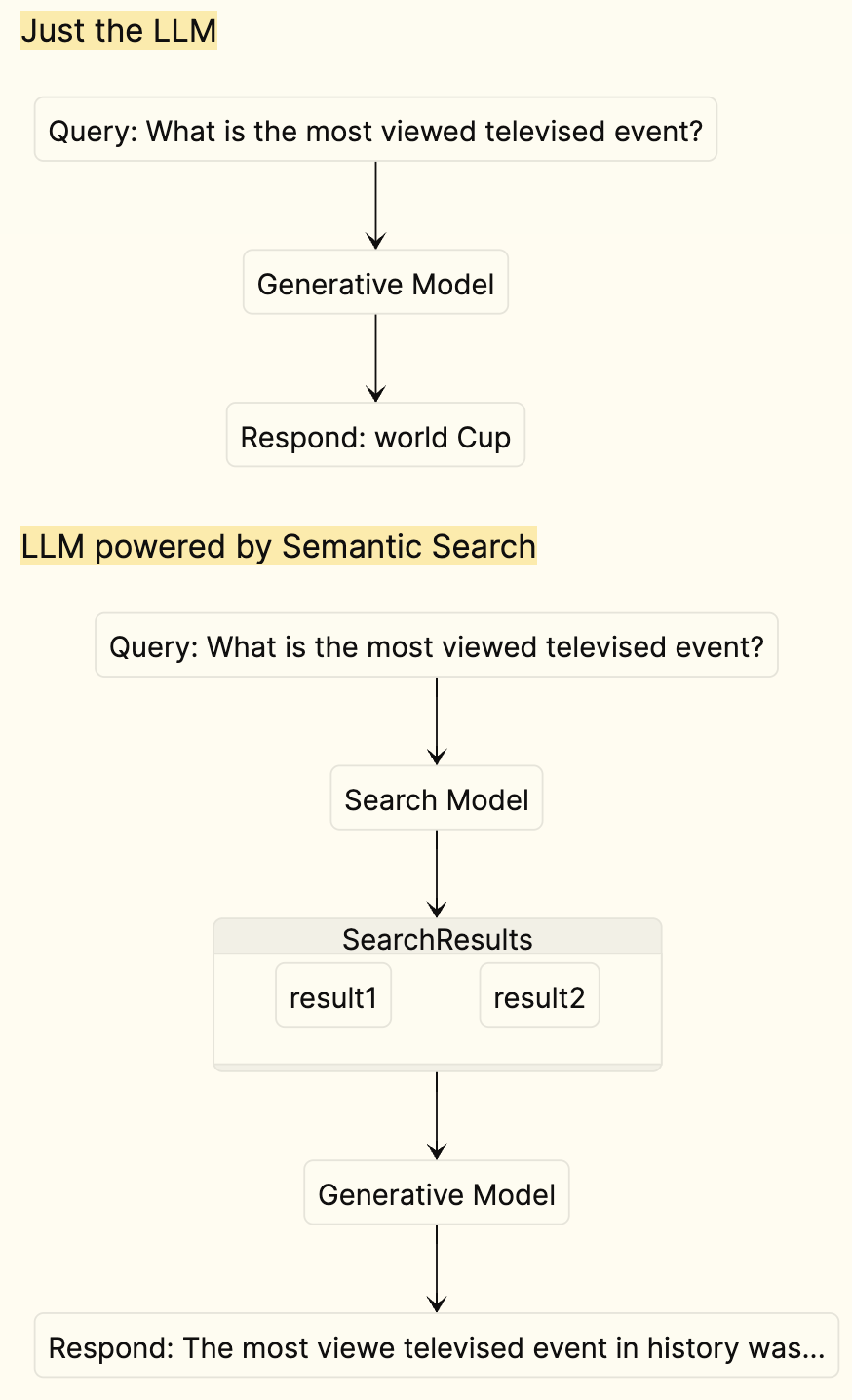
Retrieval Augmented Generation
RAG(Retrieval-Augmented Generation)是一种结合了信息检索和文本生成的机器学习模型,主要用于改进自然语言处理(NLP)任务的性能。RAG 通过先从大量数据中检索相关信息,然后将这些信息作为上下文输入到一个生成模型中,从而生成更准确、更相关的文本输出。这种方法允许模型利用外部知识源,提高了在复杂问题解决、问答、文本摘要等任务上的表现。
RAG 模型通常分为两个主要部分:一个是负责检索相关文档或信息片段的检索器(例如基于向量的相似性搜索),另一个是负责根据检索到的信息生成文本的生成器(例如,基于 Transformer 的语言模型)。通过这种结合检索和生成的策略,RAG 能够在处理信息密集型任务时,提供更丰富、更准确的内容。
Can't we just give the LLM the whole knowledge base?
How do domain-specific chatbots work? An Overview of Retrieval Augmented Generation (RAG) | Scriv
IMPORTANT
You might be wondering why we bother with retrieval instead of just sending the whole knowledge base to the LLM. One reason is that models have built-in limits on how much text they can consume at a time (though these are quickly increasing). A second reason is cost—sending huge amounts of text gets quite expensive. Finally, there is evidence suggesting that sending small amounts of relevant information results in better answers.
Indexing your knowledge base
each page might cover a lot of ground! And, the more content in the page, the more “unspecific” the embedding of that page becomes. This means that our “closeness” search algorithm may not work so well.
%%现在,我们可以将这些网页完整地传递给我们的嵌入式机器,并将其用作我们的知识片段。但是,每个页面都可能涵盖很多内容!而且,页面内容越多,该页面的嵌入就越 "不具体"。这就意味着,我们的 "接近度 "搜索算法可能会失灵。%%
What’s more likely is that the topic of a user’s question matches some piece of text inside the page. This is where splitting enters the picture. With splitting, we take any single document, and split it up into bite-size, embeddable chunks, better-suited for searches.
%%更有可能的情况是,用户问题的主题与页面中的某些文本相吻合。这就是拆分的作用所在。通过拆分,我们可以将任何单个文档拆分成一小块一小块可嵌入的内容,以便更好地进行搜索。 %%
Once more, there’s an entire art to splitting up your documents, including how big to make the snippets on average (too big and they don’t match queries well, too small and they don’t have enough useful context to generate answers), how to split things up (usually by headings, if you have them), and so on. But—a few sensible defaults are good enough to start playing with and refining your data.
%%此外,分割文档也是一门艺术,包括平均分割多大的片段(太大则无法很好地匹配查询,太小则没有足够的有用上下文来生成答案)、如何分割(如果有标题,通常按标题分割)等等。不过,有几个合理的默认值就足够开始使用和完善你的数据了%%
Summary

Other References
Meta(September 28, 2020):Retrieval Augmented Generation: Streamlining the creation of intelligent natural language processing models 这篇文章总结了一种新的自然语言处理模型——Retrieval Augmented Generation(RAG)。RAG 结合了信息检索和 seq2seq 生成两个组成部分。它可以从知识库中检索相关文档,并将这些文档与输入一起提供给生成模型,从而生成知识性更强的答案。
[2305.06983] Active Retrieval Augmented Generation 论文介绍了 FLARE(前瞻性主动检索增强生成),这是一种通过在整个文本生成过程中主动检索信息来增强语言模型(LMs)的新方法。这种方法通过使用即将出现的句子预测来指导相关文档的检索,从而解决了语言模型产生与事实不符或幻觉内容的问题。
Framework

